Print by Number :: scenario of data application
scenario of data application
數據應用腳本。
平臺的架構原則是所有的測量行為都會登錄到資料庫裡面。至於數據的應用,我這邊先用幾個工具來舉例,這是我對印刷數據應用的想像,所以先稱之為腳本狀態。
1.工具CT10:
-
用於印刷品質評分。根據滿版到位狀況、中間調(50%)到位狀態及灰平衡到位狀態給予分數,依分數高低來判斷印刷品的好壞。
Fig. 分數高的印刷品質會比分數低的印刷品質好,單一分數,簡單清楚。 -
用於印刷控制。依據數據,程式會演算出操作指令,使得下一次操作的數據會更接近目標值。
Fig. 以此例,放墨不夠,濃度由1.34升到1.48,色差可以由5.51降到3.03。

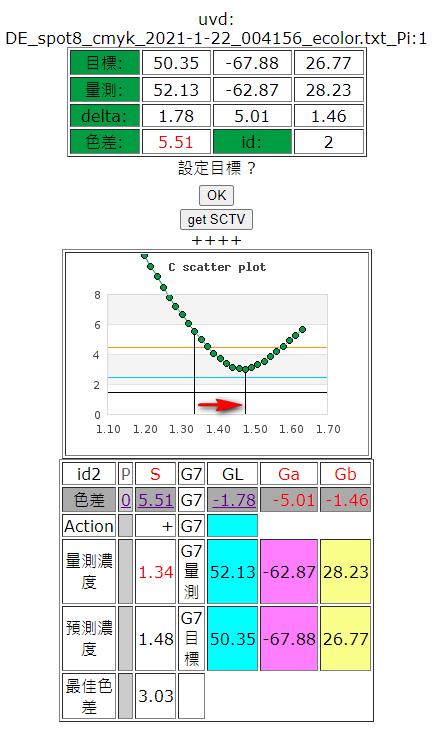
-
用於產品驗收。
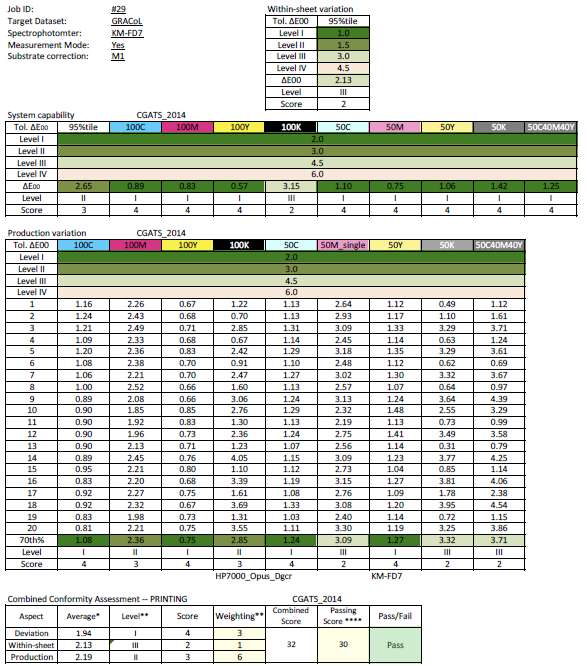
CGATS 有一個TR016 印刷品驗收規則,CT10數據足以符合"Tolerance for production variation"的條件,這裡先簡單以下面這個例子做說明:
針對production variations這一部分:每一印件取20個樣本,依這9格的色差(紙白不列入)再各別取其最大色差70%的位置,給予分級1到4級,每一個級別有其相對應的分數。合併這9格可以取得一個生產狀況的單一分數,這個分數可以用來作為產品驗收的依據。 -
用於機器狀況警示。
大多數印機師傅的操作觀念多以濃度為主,較少去關注中間調的偏離,但實際影響影像品質的因素確是中間調要大於滿版。CT10的數據模式在同時反映滿版與中間調的位置時,很容易察覺到中間調異常的問題。
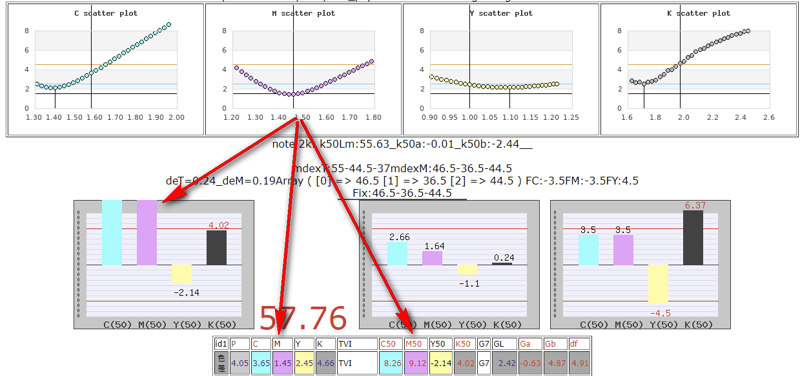
Fig .M座滿版濃度已到位,TVI高達9(正常值為±4),顯示M座網點擴張太大,如果此數據型態持續發生,系統將自動發出訊息給管理單位,系統人員需介入處理。
我自己設定的TV警示規則大概是這個樣子:
1.當滿版已到位,但TV高於標準6%或低於標準6%,則系統發出警示。
2.當TV在標準範圍,但主色de大於8,則系統發出警示。
2.工具CT3:印版日常撿查,紀錄印版每日版底、滿版濃度及50%的位置,偏離設定,即發出警示。
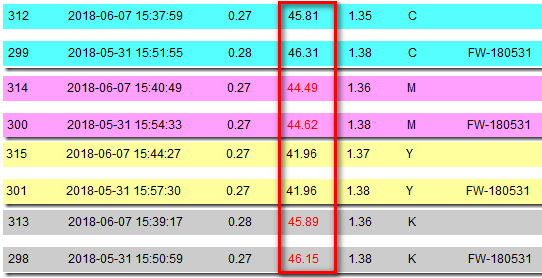
3.工具CT21:印版版調每月例行檢查,檢查5%、10%~90%、95%的版調位置,若脫離標準範圍,則發出警示信息,通知系統人員介入。
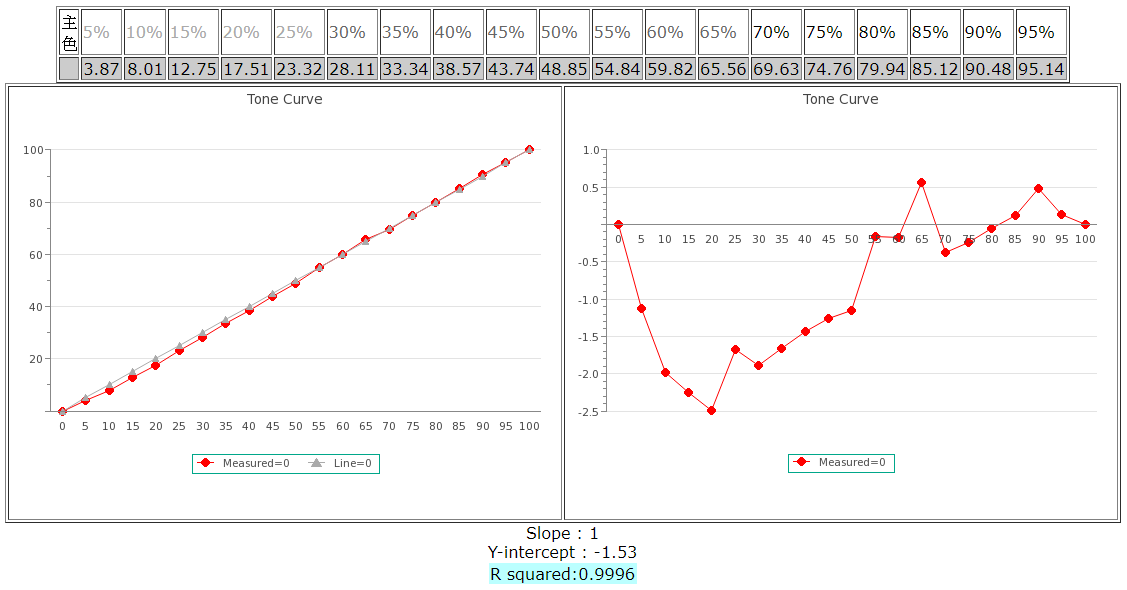
4.工具CT84:印機版調每月例行檢查,檢查5%、10%~90%、95%的版調位置,若脫離標準範圍,則發出警示信息,通知系統人員介入。

5.CT84印機版調數據比對CT21印版數據
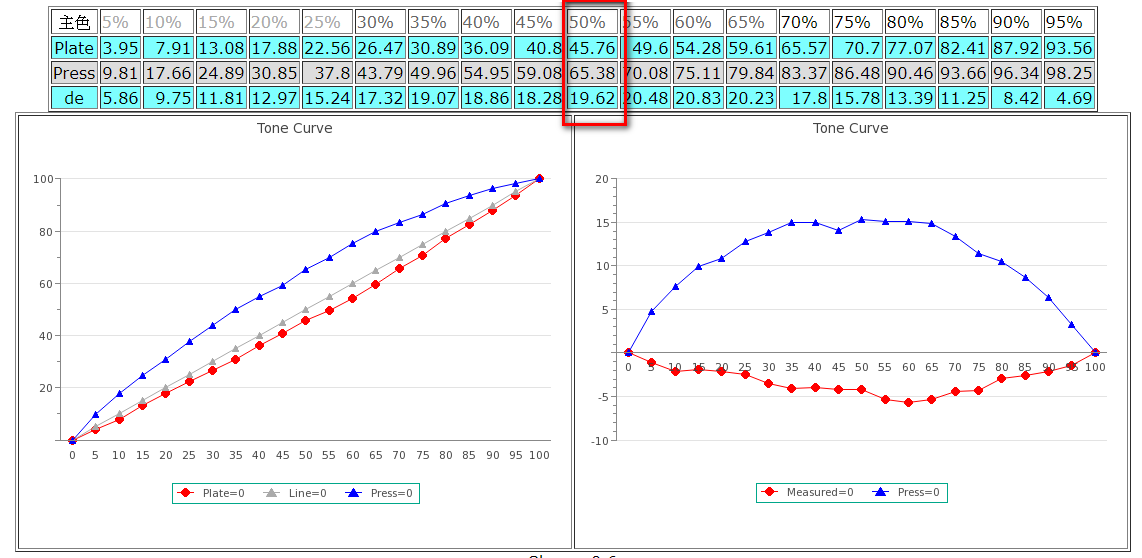
Fig.圖示50%處印機TV值為65.38,屬在標準範圍內,但比對印版50%處為45.76,所以印機端實際擴張為19.62,一樣必須列入印機警示。
如果印刷廠能夠掌握上述數據,並且能夠及時介入解決,印刷品質會出錯的機率就可以降到最低,但普遍看下來很少印刷廠會去做了這些數據的監看。原因大概會是:
1. 經驗式的工作法則,不太會去想這些,憑經驗去操作,印不到就去找印前來修圖或修版。
2. 沒有接觸過這方面的知識,自然就不會去執行。
3. 已經能夠瞭解到這方面的知識,但沒有順手的工具,或是執行起來太麻煩,所以也就不做了,或者是做的頻率非常的低,比如說半年才一次。
當然還有一個有重要的因素:印刷廠的沒有一個責任的歸屬者來負責這些資訊,也就是我說的系統人員。找不到人負責,自然就不會有這方面的執行數據。
在我設計這些工具的概念裡,就是要儘可能的簡化操作程序。以i1 strip reading 的工作方式,即使是樣本數最多的CT84工具,i1 4次掃描下來,花不到一分鐘時間就能夠有結果。

Fig. CT84 印機TV導表,i1 4次掃描下來,1分鐘時間就能夠有結果。
https://www.youtube.com/watch?v=ZX-VVNg3rIM&t=10s
簡便的工具,快速的反應執行結果,應該可以增加印刷廠願意去監看這些數據的意願。
一旦建立起數據監測的機制,經過長期大量的數據收集,這些大數據的分析可以用在幾個方面。
1.控墨指令的優化,以CT10為例,濃度差該轉換為幾格的控墨鍵動作應該可以被關聯出來,印機師傅的控墨動作應該可以越來越順暢,越快的達到目標值。更細緻的印刷機行為如降墨時色彩改變較慢、加墨時色彩改變較快,這些細緻的變化也能夠經由數據分析及機器參數關聯出來。這些關聯出來的參數如果可以回饋到印刷機,最終可形成更優化的自動控制。
2.在印刷機的滿版位置與中間調位置能否同時到位的警示規則上,累積的數據可以將規則定義得更細緻。必要時再關聯到CT21印版數據與CT84印機版調數據,可以更精確的關聯出更換橡皮布的時機,不像現在還是由師傅自己在做判斷。
3.印機放墨指令補償:比對上光、上膜前後的色彩數據差異,可以在印機操作時即加入補償差異,使得上光/上膜後的色彩數據一樣能跟上標準值。同樣的邏輯也可以用在乾墨/溼墨的色彩補償,使得溼墨的操作數據在乾燥後一樣能跟得上標準值。

Fig. 亮面上光,50%TV值增加將近7%,滿版濃度略增。(左 為TV,右為濃度,藍色為上光數據)
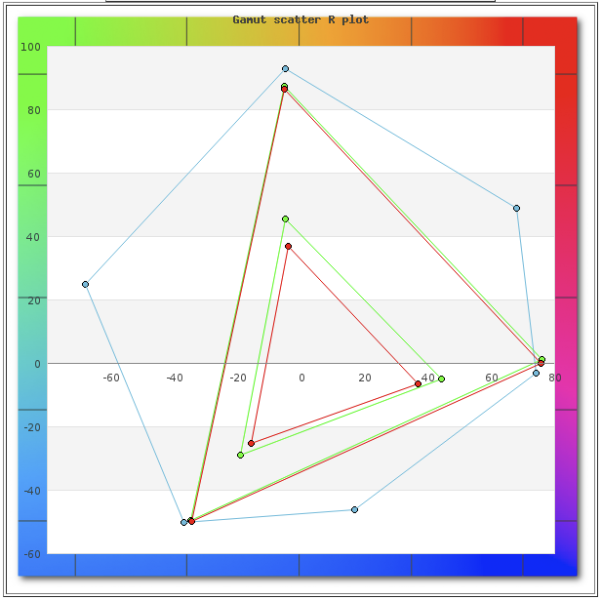
Fig. 從ab圖看,亮面上光在滿版位置差異不大,50%處飽和度會加大。(綠色為上光)
4.依印件內容自動判斷濃度優先或是版調/灰平衡優先。
這裡要做一些說明,在一個狀態良好的印刷系統裡,控墨行為沒有所謂濃度優先或版調優先這回事,但實際上是印刷機變數太多,一定會碰到滿版跟中間調無法同時到位的情況,這時候的操作就必須有一個判斷:是要以滿版濃優先還是以中間調優先來處理。
大多數的師傅都會以滿版濃度的觀點來處理,因為這是最直接取得的數據,是最方便的處理方式,但對於以影像為主的印刷品,網點部分佔據絕大多數的印刷面積,這樣的印刷品硬要以濃度為主的觀念去處理,影像部分是會有問題。這時候以版調優先會是比較好的選擇。相對的,對於包裝印刷、或是一些強調色彩鮮豔的宣傳品,滿版或特別色的佔比會大於網點部分,這時候選擇濃度優先會是比較好的選擇。
以上的舉例可以歸納出類似這樣的邏輯規則:
當機器無法滿版與中間調同時到位時,印機操作必須在滿版優先與版調優先做選擇。區分原則大致為:當印刷品的滿版占比大於某一個比例時,則選擇滿版優先,小於某個比例則選擇版調優先。更細緻的區分,可能還是要加入別的參數判斷,或者在不斷的數據學習中達到最優化的規則。

Fig. 依版面滿版佔比決定濃度優先或是版調優先。版面占比資訊可以從CIP3的ppf或者直接掃描影像tif檔取得。
以上,是我對印刷數據運用的部份想法,影像/色彩這種物理現像一但能轉換成數字,我們就可以運用各種物理/數學/統計的工具去處理。要做有効的管理、要自動化,都不能缺少數據。
所以,不管怎麼樣,要能取得數據,才能有將來各種可能性的想像。而且數據要夠多,才足以餵給AI或是Machine learning做更細致的優化。
當用雲的方式來做這種服務的時候,所收到的數據就不再限於單一廠家,而是這個產業,當有越多的數據可以學習的時候,才是這個產業智慧生產的基礎。

Tags: Plate
無迴響
 Comments RSS
Comments RSS
 TrackBack Identifier URI
TrackBack Identifier URI
No comments. Be the first.
 Leave a comment
Leave a comment
