27 12 月, 2023 () Uncategorized › Administrator › No Comments
I’m lazy.
我就懶
製作工具的基本動機是:懶!
同樣件事情能不能用最少的步驟、最少的設備、最少的時間去完成它?
舉例說,當想知道這個印刷品的品質好不好,最快的方式是什麼?
在我的工具架構中,CT10 是最迅速有效的工具。刷過去5秒鐘就會知道現目前印機狀態滿版的位置,中間調的位置及灰平衡的狀況。
目前的程序是由SDK把i1的光譜數據帶給php運算,然後顯示出結果。
你這樣已經夠精簡了,我還想懶成什麼樣子!
就為了這個東西,斑馬尺。

Fig. Zebra ruler
從i1pro2開始,在做strip reading時,如果要取得M1模式,必須經由斑馬尺來做讀取(Pro2 M0 模式不需斑馬尺,Pro3 則是 strip 模式都需斑馬尺)。包包裡已經夠多東西了,實在不想再多這個重量。
找到 i1Pro Chart Design Rule 文件裡,有這樣的敘述:每一個相鄰色塊超過20個deltaE,可以不經過斑馬尺。

Fig. from i1Pro Chart Design Rule.相鄰色塊超過20個deltaE,strip reading 可以不經過斑馬尺。
於是舊的CT10的格式變成這樣。


Fig..CT10,上面為舊格式,下面為新的格式。
實際操作下來,確實可以不用斑馬尺。

Fig. 不用斑馬尺,i1Pro3就可以做strip reading。
把數據拿出來分析一下,目前排列最低色差發生在K50與C50之間,色差為30,能夠符合 Chart Design Rule 規則。
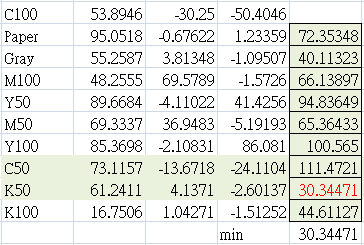
同樣的邏輯,當然也可以放在CT25這個工具上面。於是CT25也有新的格式。


Fig. CT25 工具,上面為舊格式,下面為新的格式。
CT25新格式的數據參考如下 ,最小色差發生在paper與c50之間,約deltaE33,符合低於20個deltaE的規則。
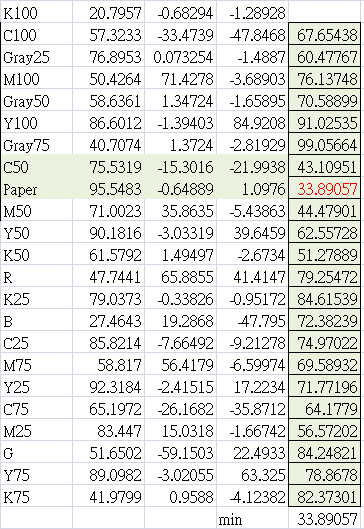
新版格式,確認每個色塊都超過20個deltaE,實際測試確實能夠使用。這樣以後就不需要再帶那根斑馬尺了。
都說科技來自人性。這個本性其實就是”懶”。但裡面更重要的是,我們如何能用最懶惰的方式,去達成我們設定的工作目標。
要懶,又要達成工作上的目標。我必須學習光譜計算、學習PHP、學習Autoit、學習驅動i1 sdk的c++、學習導具格式的xml、學習資料庫語言mysql、要瞭解ISO、idealliance各種標準的定義與規格、要不斷的測試程式語言的邏輯……。這個“懶”字,不容易啊!
要懶惰,又要能達成工作目標,關鍵就是邏輯。衹要能把邏輯講清楚。把這些工作邏輯用程式方法堆積出來。是有機會可以做到又懶惰,又能達成工作目標。
Filed under: Uncategorized › Tags:
27 12 月, 2023 () Uncategorized › Administrator › No Comments
single purpose tool-spot color
特別色-單一功能工具
CMYK 主色色差在ISO 有明確規定(CYM de00<3.5 K. de00<4.2)。 特別色色差並沒有官方規定,如果有人問起,我一般會說小於3個de00 吧!
以印刷品買方來講,當然是色差越小越好,對生產者來講,則是越大越容易操作。既然沒有官方規定,比較正確的方式應該兩方一起協調,共同制定寬容範圍。
業界裏有一種運作方法叫做特別色承認書,由生產方定出生產的上限與下限由買方來簽認,這樣的作業方式多了前行的承認書作業,但確實是一個對雙方更有保障的工作方法。

針對這樣的工作模式,我組合了一個工具, 技術成分沒有很高,主要就是作業方便。
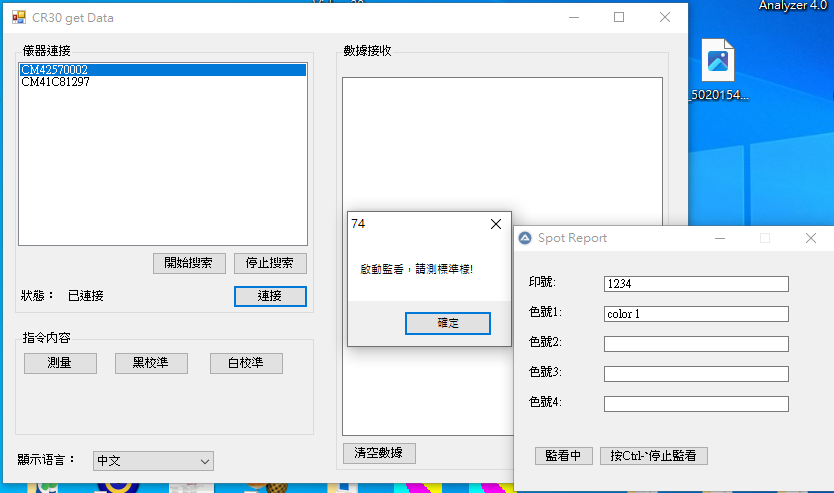
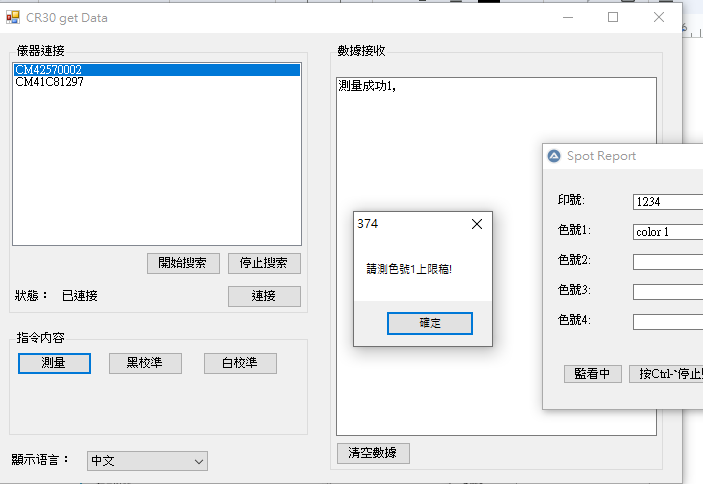
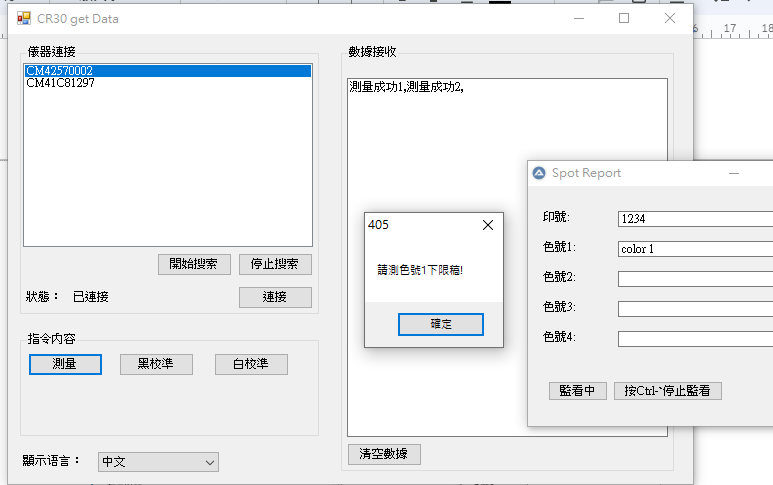
Fig. 監看程式提示測量標準稿、上限稿與下限稿。
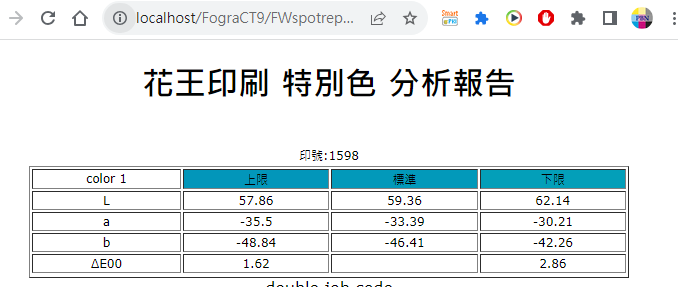
Fig. 三個測量點量測完畢後即時取得報告。
使用者依指示測量“標準”、“上限”、“下限”三個量測點即可形成報告。純粹就是一個方便運作的小工具。
既然系統已經有數據記錄,這些數據當然可以帶到生產場合,於是衍生了特別色的生產操作工具。
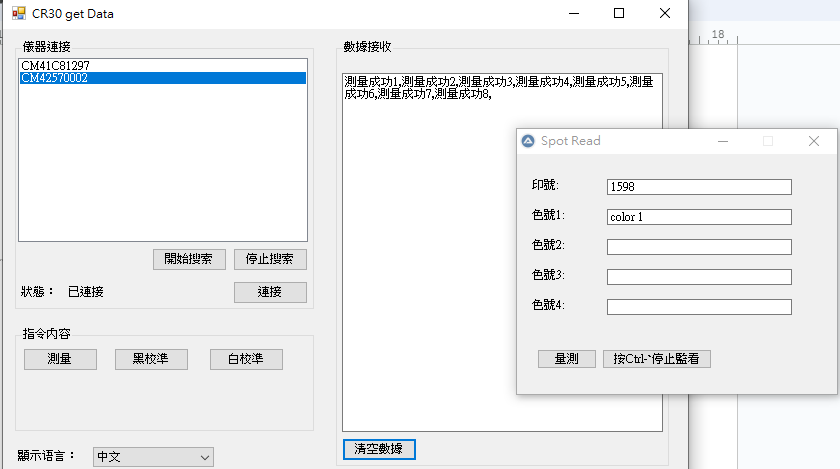
Fig. 生產工具介面,把印號調進來即可隨時監看特別色是否在上下限。
生產時把印號調進來,師傅在操作時就可以清楚知道這個印件有沒有在上下限範圍之內。這種比對方式會有4種狀況:高於上限則標示呈紅色、介於上限與標準之間表示呈綠色、介於標準與下限之間標示呈綠色、低於下限則表示呈紅色。
簡單講,看到綠色就是OK,紅色則不通過。如果呈現紅色,依光譜濃度訊息,也能很快的操作出合格的樣本。這樣的工作設定,期使能在印刷階段就同時完成品管。
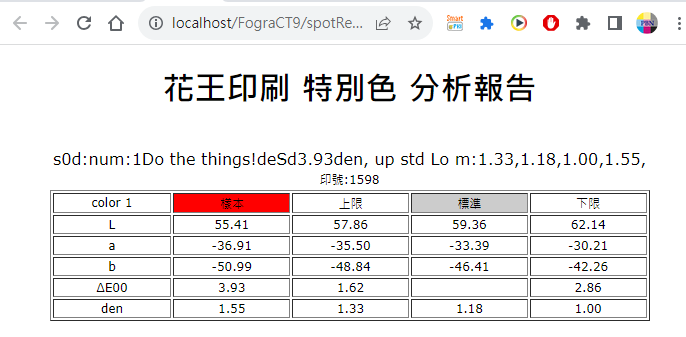
Fig. 高於上限則標示呈紅色,以光譜濃度資訊,再減墨量就可以進入合格範圍。
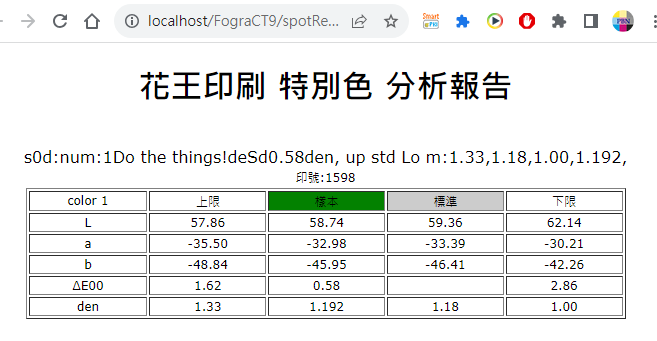
Fig. 呈現綠色則表示在合格範圍,再減一點墨效果會更好。
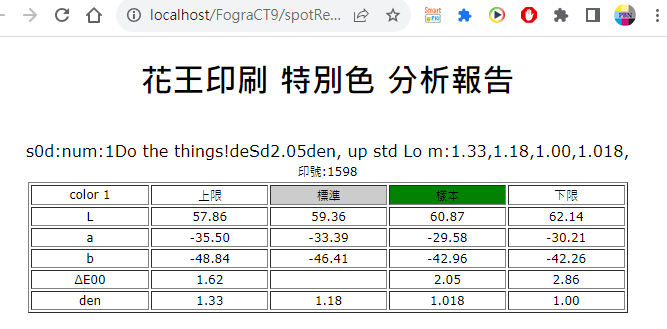
Fig. 呈現綠色則表示在合格範圍。再加一點墨效果會更好。
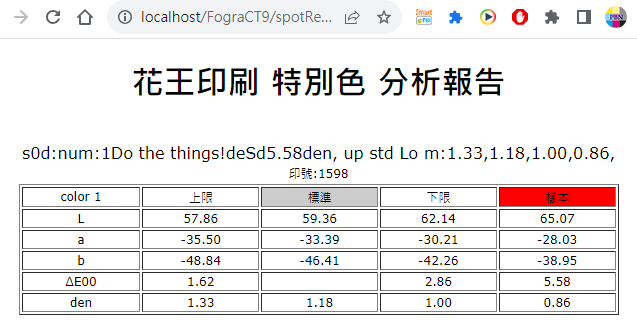
Fig. 高於上限則標示呈紅色,以光譜濃度資訊,再加墨量就可以進入合格範圍。
簡單的數據反應,師傅可以即時知道現在的生產品合不合格?如果不合格,也有清楚的操作方向。這樣子幾乎是在生產階段就已經完成品檢,可以減少很多後續品管與業務端的工作。
簡單的概念,簡單的工具安排,確實能提昇廠裡的工作效能。
整個工作架構之前,還要向前延伸一項建置成本的優勢。
會製作這個工具的前因是,單位裡一個三十幾萬的積分球光譜儀壞了,之前用來形成報告的軟體也用不上來,在決定是否要買新的光譜儀之前,來詢問我能有什麼樣的工作方式?
這個工作架構裡,衹要能提供穩定(低器差)的光譜數據來源,在一個相對概念的操作下,只要數據來源都是同一支,絕對精度低一點的儀器一樣可以勝任這樣的工作,因此目前架構在一個不到萬元的d8光譜儀下工作,邏輯上及操作上都沒有任何問題。
當然,如果有絕對精度的需求,還是必須取得高階的儀器。只要能取得SDK,後續工作邏輯是相同的。

Fig. 在一個相對概念的操作下,只要數據來源都是同一支,絕對精度低一點的儀器一樣可以勝任這樣的工作。
以上,單一功能工具建構完成,發佈及使用都非常精簡。預計發展手機版本,提昇便利性的移動性。
短影片,請參考:
#特別色工具
#printbynumber
Filed under: Uncategorized › Tags:
26 12 月, 2023 () Uncategorized › Administrator › No Comments
3 points gray correction
上一回的工具開發成功的以單點修正來修正PDF的版調,那幾行簡短的程式碼在實際生產上會是非常有效的工具,但如果是在要取得印刷認證的場合(如Fogra PSO 或 idealiiancd G7),這個簡捷的單點控制不一定能取得全面符合的數據。
我之前的工具發展有一個3點灰平衡修正(25%、50%、75%)。可以很快地取得G7 Grayscale成果,配合Beer’s Law 工具,可以很快的達成G7 targeted規格。
上面提到的語法是經由ghostscript 帶動 Postscript 去改變PDF 的版調,以單一50%處用exponential 函式曲綫去帶動整個版調修正。如果要用三點修正的方法,單一exponential 是帶不出來的,估計polynominal regression 或 spline interpolation 都做得到,我不好估計是polynominal regression比較好,或是spline interpretation會比較好。不過可以確定 spline interpolation在曲綫的分布會經過我標示的5個點(0%、25%、50%、75%、100%),所以我試著要用 Spline interpolation的方式來達成3點灰平衡修正的功能。
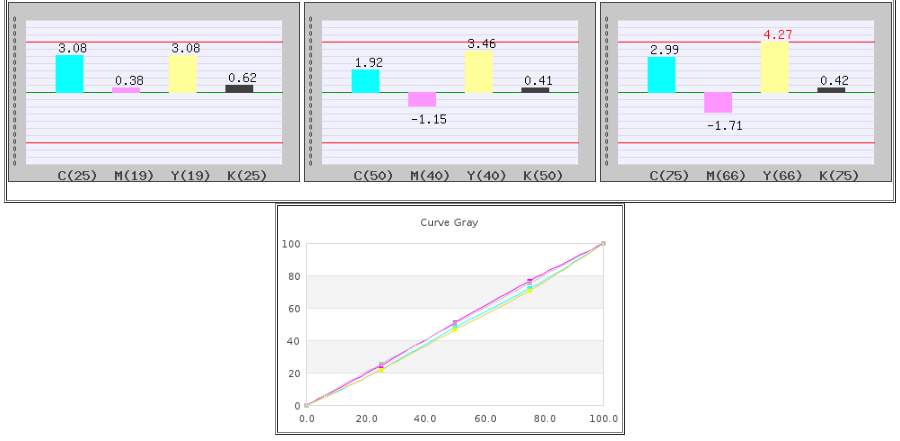
Fig. 3點灰平衡修正案例
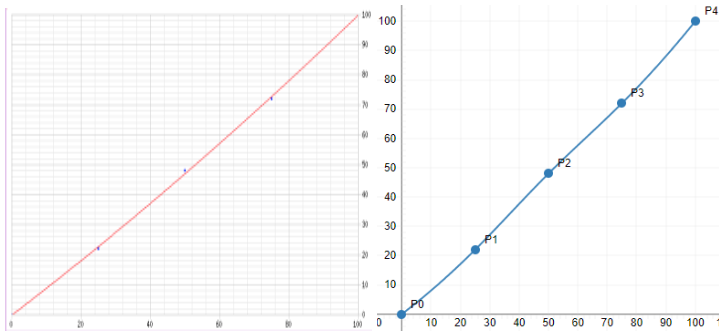
Fig. 同一組版調修正數據,左邊為polynominal regression,右邊為spline interpolation,可以看出spline interpolation 會經過數據標示的5個點。
Spline interpolation 是我以前沒做過的題目,自然又是找上ChatGPT了。
ChatGPT這次很快的就回應出可執行的程式碼,以python套用 scipy.interpolate library 裏的CubicSpline 功能,依據我給的3點修正數據(加上0%及100% 總共5組數據)很快就能取得Spline 版調修正曲線。
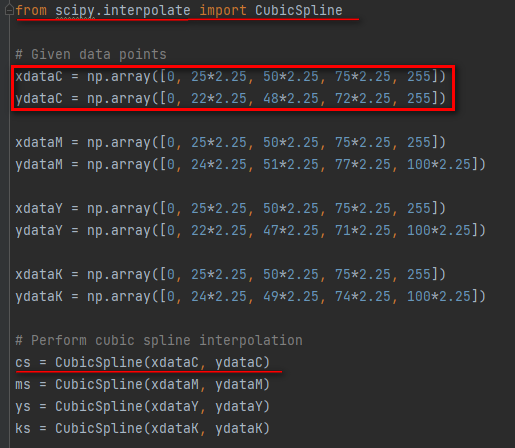
Fig. 以python套用 scipy.interpolate library 裏的CubicSpline 功能,依據3點修正數據(加上0%及100% 總共5組數據)很快就能取得Spline 版調修正曲線。
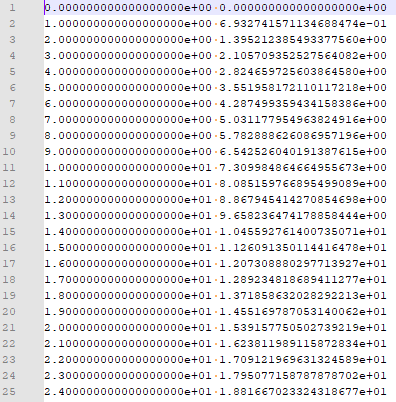
Fig. 由scipy.interpolate library 裏的CubicSpline導出的版調修正表。
接下來就是將這個修正曲線套用到影像檔裡面。上回提到用ghostscript以單一50%處用postscript exponential 函式曲綫去帶動整個版調修正,這裏要用到整個Spline transfer curve 套用到整個版調,經過很長一段時間在ChatGPT的各種努力,目前還是駕馭不了postscript的語法。退而求其次,還是先直接在影像檔(像素檔)做版調修正,而不在PDF用postscript做版調修正。
同樣的,ChatGPT很快的就提出了工作方法。一樣是python,使用PIL library可以處理到影像中每一個pixel的內容。
下面是ChatGPT回應的一段程式碼,裡面的tone_curve就是來自之前的spline interpolation curve。PIL 的putpixel function可以將轉換過的CMYK資料寫入原本pixel的位置。如此就可以完成像素檔的版調轉換。
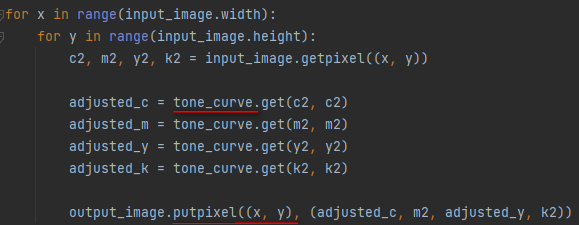
Fig. ChatGPT回應的一段程式碼,裡面的tone_curve就是來自之前的spline interpolation curve。PIL 的putpixel function可以將轉換過的CMYK資料寫入原本pixel的位置。
照說到了這裡就已經完成CMYK檔的版調轉換,但是一個一個pixel寫進去實在是太沒有效率了。
把問題反映給ChatGPT,也很快得到有效的回應。
用numpy library 將圖像中的像素用陣列的方式來處理,速度就能快上許多。
Fig. 用numpy library 將圖像中的像素用陣列的方式來處理,速度就能快上許多。
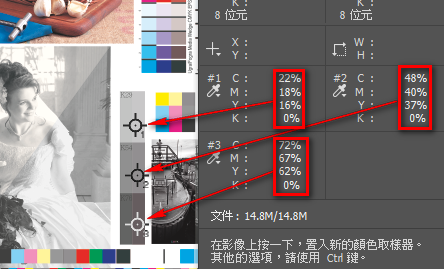
Fig. 修正過的圖檔,確實有照3點修正的數據來改變版調。
以上,經由ChatGPT的回應,成功的對影像檔做3點灰平衡修正。我已經用3點修正配合Beer’s Law成功拿過幾次G7 Targeted。這一次又多了一個可以運用的工具。
Filed under: Uncategorized › Tags:
26 12 月, 2023 () Uncategorized › Administrator › No Comments
Coding on PDF
跟ChatGPT磨了三天,發出了上百道問題,就為了這幾個程式碼!
"{0.81 exp}{1.02 exp}{0.86 exp}{0.83 exp} setcolortransfer"
先說這幾個程式碼是幹嘛用的?
這一段程式碼可以讓 pdf 檔的C50%降到43%、M50%升到51%、Y50%降到45%、K50%降到44%。
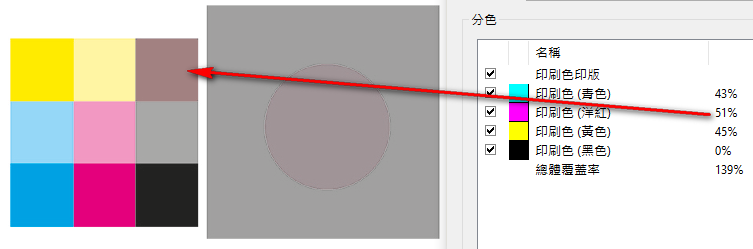
Fig. "{0.81 exp}{1.02 exp}{0.86 exp}{0.83 exp} setcolortransfer" 這一段程式碼可以讓 pdf 檔的C50%降到43%、M50%升到51%、Y50%降到45%、K50%降到44%。
這幾個程式碼在我的工具架構裡面會是非常重要的一段。
從一開始撰寫工具程式,目的就是要以最精簡快速的方式來達成輸出的品質控管。
從最早的Excel Macro到後來能用SDK取得光譜數據交由php、autoit、javascript、python…做後續處理,每一次的累積都是為了加快速度與方便性。
當我們要把輸出品質帶到某一個位置(灰平衡)的時候,不外乎動機器、動印版,或是動影像檔。
我的工具發展一直在這幾個面向做快速的輔助。
之前其中一個工具可以輸出.acv檔來改變影像檔,它的程序是:用Photoshop打開影像檔,載入acv來改變版調,儲存檔案,然後供輸出使用。
這個acv工具在使用上的問題是:
-
必須開啟photoshop。
-
只能處理像素檔。
-
批次處理還需要另外做程序。
而實際的生產狀況是以pdf為主,acv的方法可以處理問題( PDF轉JPG/TIF,套用曲線後輸出),但在實際的生產單位効能太低。
如果曲線功能能直接用在PDF檔,不是更有效率,更直接嗎?
這個題目一直都存在,但一直覺得沒有能力處理。
ChatGPT 的出現讓我重新開始去接觸以前不敢做的題目。
比如前一個以相機影像做爲 icc Profile 數據參考的案例,在同事的模板與ChatGPT 不斷的追問下,成功的以Python Open CV達成從影像中成功擷取出必要的影像範圍,讓整個工作流程更為流暢。

Fig. 以Python Open CV 自動截取紅框與藍框的範圍。
Fig. Python OpenCV code on maskout Red Frame.
以指令改變PDF版調這個題目,也就這樣跟ChatGPT磨了三四天。
ChatGPT 提供的大原則基本上沒有問題,具參考價值,但細節的處理不夠精確就始終得不到可以運作的程式碼。
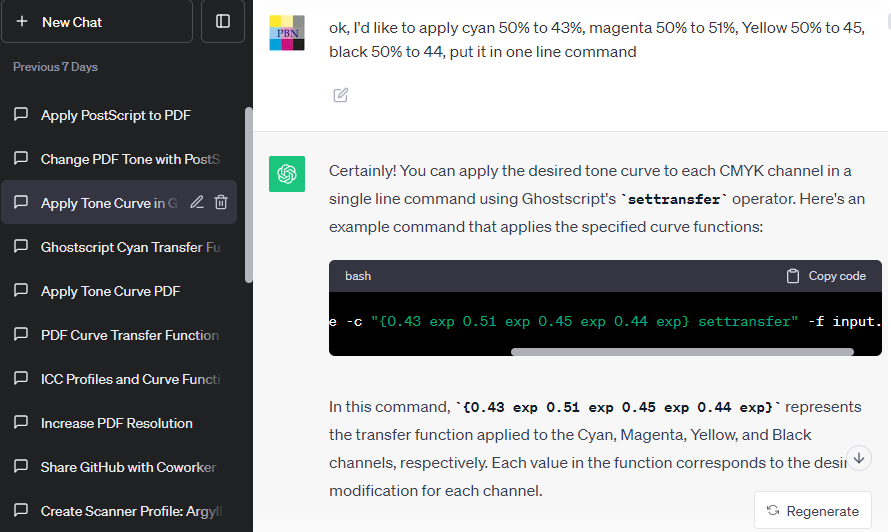
以我一連串其中一個發問為例:I’d like to apply cyan 50% to 43%, magenta 50% to 51%, Yellow 50% to 45% and black 50% to 44%, put it in one command line.
ChatGPT 給我這樣的碼:
gs -o output.pdf -sDEVICE=pdfwrite -c "{0.43 exp 0.51 exp 0.45 exp 0.44 exp} settransfer" -f input.pdf
怎麼跑都跑不出我要的結果。
各種方式的追問,始終得不到我要的結果。不是結果錯誤,就是出現錯誤訊息,無法運作。
一樣經由ChatGPT去瞭解postscript的指令與語法,終於歸納出我要的規則。
ChatGPT提出的語法,至少有兩個錯誤一直沒有被處理到,導致鬼打牆的三天來套出不出正確的碼。
-
即然用的是exp(exponential, 指數函數) curve function,就不應該直接把0.43(50% to 43%)放上去,應該放相對對數(log)。
-
當處理的是CMYK檔案時,是一種減色法的格式,與加色法(RGB)版調呈反向進行。所以要取的對數,還必須用1去減。
兩個問題理清之後, ChatGPT提供的語法就可以派上用場,得到正確的結果。
把規則理清後的結果是:
當要把50%處降到43%時,要取的系數是: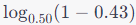 =0.81,
=0.81,
in excel: =LOG((1-0.43),0.50)
配合ghostscript的單一指令為:
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output.pdf -c"{0.81 exp}{1.02 exp}{0.86 exp}{0.83 exp} setcolortransfer" -f input.pdf

Fig. pdf 原檔(左)與ghostscript處理過後的pdf檔。
以上,花了三天取得的單行程式碼,配合灰平衡邏輯,可以實現批次pdf版調改寫,以最快的效率達成灰平衡的品貭控管。
雖然祇有幾十個字的程式碼,但在我的工具架構裡,很重要。與 photoshop acv的工作方法相比,快上太多了。
Filed under: Uncategorized › Tags:
26 12 月, 2023 () Uncategorized › Administrator › No Comments
A very efficient G7 exam tool.

年度續證,做一下記錄
每次做G7都是不同的狀況,會遇到新的問題,會產生新的做法,新的工具。
我做G7 Targeted 主要是兩個工具:CT25 與CT28x2(G7 verifier)。
做G7的第一個動作是確定放墨濃度,CT25裏面可以用Beer’s Law預測CMYK最佳放墨量,再利用6角圖去修飾RGB的位置。
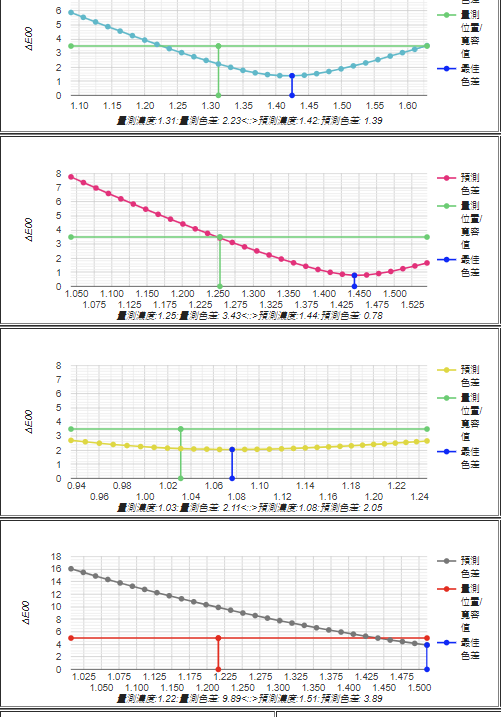
Fig. CT25工具中以Beer’s Law 預測最佳放墨
Fig. CMYRGB六角度用來推斷RGB位置。
CT25中的三組階調值(CMYK 25%,50%,75%)可以用來觀察印機網點擴大狀況。
三個灰平衡色塊(CMY 25,19,19、50,40,40、75,66,66)可以經由灰度差(Δch)與亮度差(ΔL)預測CMY的版調修正量。
一個CT25資料下來,放墨、版調、灰平衡的現場狀況可以一次掌握,修正量也都有工作指令。CT25是一個非常有効率的工具,C9、gmi也是在相同的基礎對印刷品做評分,我則更延伸出工作指令(操作方向與操作量)。
日常印件以CT25來做評測與工作指令已經相當足夠。要做認證的話,CT25扮演重要的前置工作角色,真要通過認證,CT28x2(G7 verifier)才是一個必須達成的目標。
我一直習慣的用這兩個工具來做G7考試,今天倒是遇到了問題;這一次的Testform, G7 verifier 只放單邊,這樣我就不能確保兩邊的p2p都能通過驗証。再者,就算兩邊都放有G7 verifier,我也不能確定即使兩邊的verifier 都通過數據門檻,兩邊p2p的數據也一樣能通過數據門檻。因為考試最終認定的是p2p數據,而不是verifier 數據。

Fig. G7 Verifier 與 p2p 並不一定會得到相同的數字,因此新的工具直接從p2p上讀取數值,降低影響變數。
因此,在現場臨時改寫一個工具,簡單講,這個工具直接讀取p2p內第四行及第五行,格數是25×2,只做Grayscale驗證。
當時想到的工作邏輯是,由CT25確保放墨狀態之後,再執行p2p內的第四第五行去確認Grayscale 狀態,這樣會是一個最有效的G7考試執行方式。
執行時間最精簡,總共祇要在控制臺上讀取三個strip,就可以將G7帶到位。相對於正常作法須割取p2p色塊並讀取12個strip(300組數據);這個做法在效能上要快上許多。也由於判讀的速度很快,現場可以進行更多次數的測試,去試出更好的數據結果。
也由於grayscale數據直接取自p2p,也更能確保G7驗證單位讀取的部分與我讀取的部分是一樣的,不會因為verifier 與 p2p 位置不一樣而讀出不同的數據。
工作邏輯整理完畢,這裡將當天的工作交代一下。
第一個CT25放墨量確定下來之後,就知道今天是有狀況了!如圖示,在最佳放墨量的狀況下,網點擴大誇張的高,高於標準10個%以上,心裡有底,大概一次改版不見得能夠做得回來,第一個改版指令就是先把中間調拉10個%下來吧!
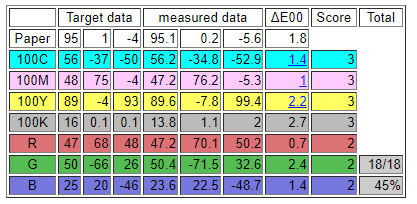
Fig. 用CT25決定最佳放墨量。
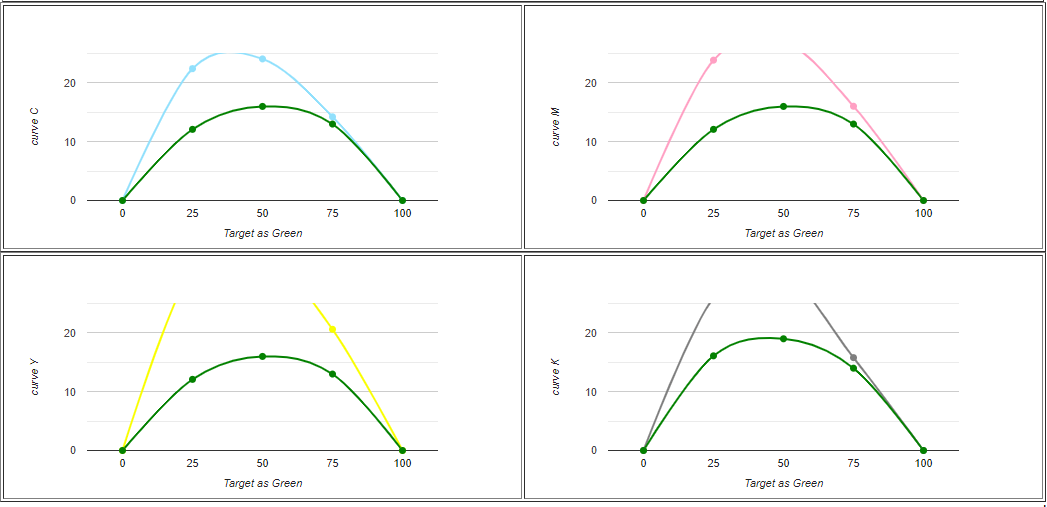
Fig. 滿版到位,中間調網點擴張誇張的大。
跟領機反應網點擴張異常的大,會是哪方面的原因?領機提到現場溫度太高,印機旁柱子上的溫度已經是28.4度,估計機器本身會是30度以上,這樣的溫度讓墨的流動性太大,會造成網點擴張變得太大。這個狀況現場沒辦法即時處理,我衹能依賴改版調去把這個現象修正回來。

Fig. 印機旁的溫度高達28.4,高溫已經影響油墨的流動性,造成網點擴張異常的大。
雖然網點擴張太大,但分佈的狀況倒是維持得很好,R2達0.94,估計不會有太奇怪的修版數值,單點50%修正說不定就可以把G7拿下來。
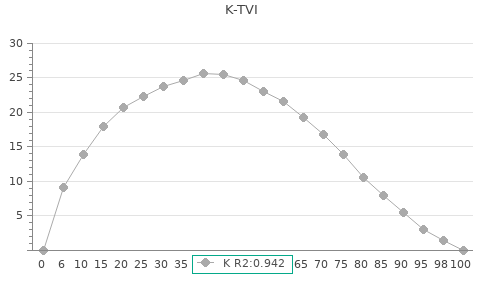
Fig. 第一次grayscale verifier 取㨾,網點擴張是很大,但是分佈的狀況還不錯,R2達到0.94,估計不會有太奇怪的修版分佈數值。
第一次修版之後,K及CMY版調(亮度差ΔL),一次到位,但灰差(Δch)還差一點,主要分佈在75%上下。從數據上觀察,是75%處黃版異常的大,估計很難從印機上調回來,決定直接修黃版75%處。
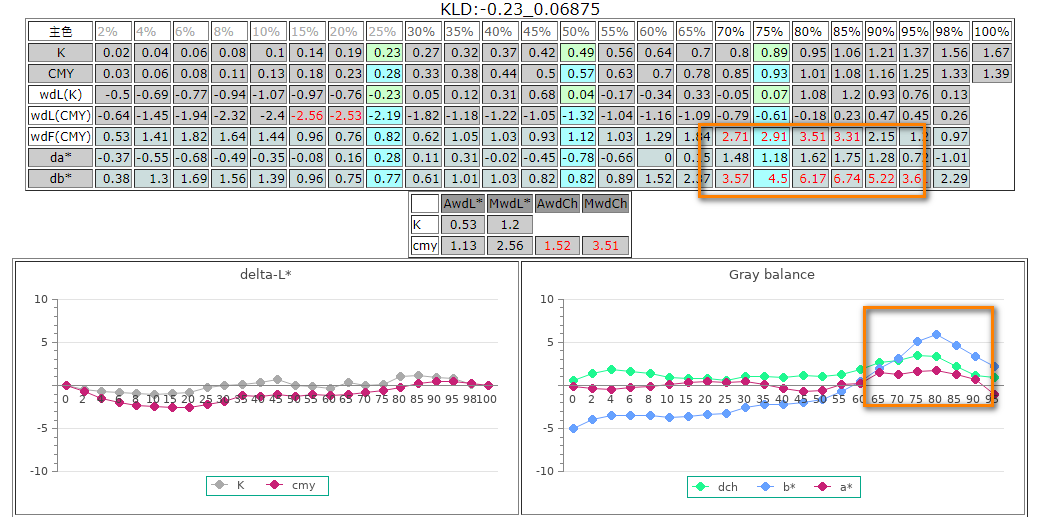
Fig. 第一次修版之後,K及CMY版調(亮度差ΔL),一次到位,但灰差(Δch)還差一點,主要分佈在75%上下,從數據上觀察,是75%處黃版異常的大,估計很難從印機上調回來,決定直接修黃版75%處即可。
再一次修正後Grayscale已能達標,配合CT25上CMYKRGB皆已到位,G7 Targeted算是拿下來了。
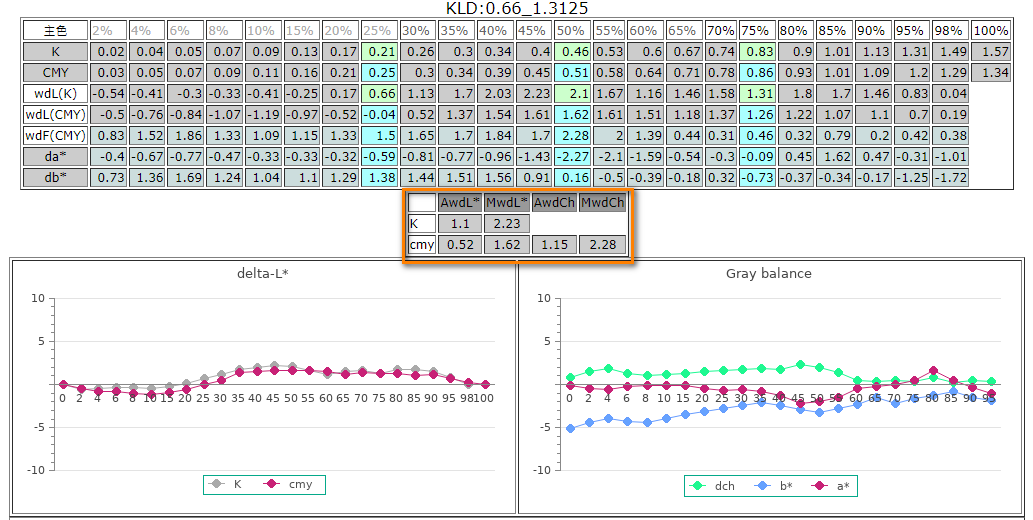
Fig. 再一次修正後Grayscale已能達標,配合CT25上CMYKRGB皆已到位,G7 Targeted算是拿到手了。
送件後一個多星期後,G7認證單位回覆通過G7 Targeted 續證。在機器狀況很糟的狀況下,通過幾個簡單的工具一樣可以把G7拿到手,看這數據還不算太差呢,證實這些工具還是一樣簡單有效。
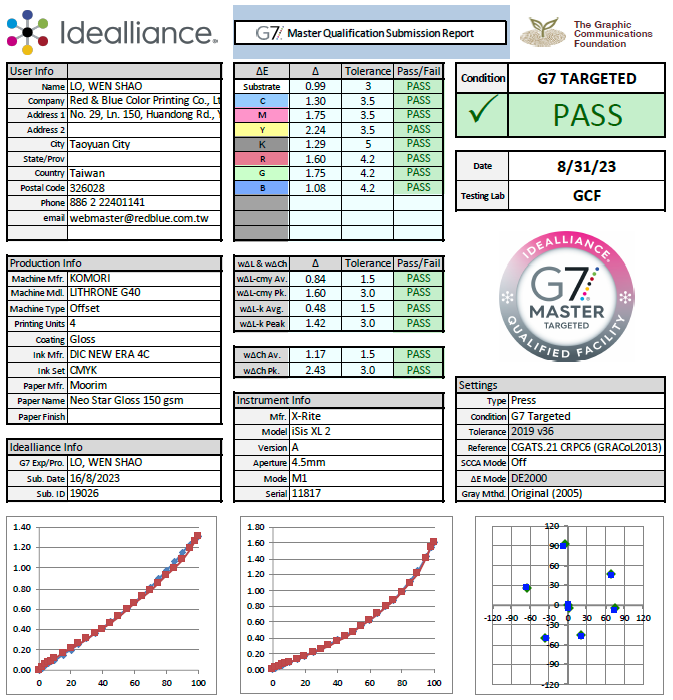
Fig. G7 Targeted 續證通過。

Fig. 現場寫工具。
後續再把工具做了一些整理,我的系統工具上增加了G7_50、G7_125及G7_50+6三個工具。
G7_50 就是上述當時在印刷厰改寫的Grayscale工具,後續再增加了G7_125及G7_50+6兩個工具。
G7_125是直接掃描p2p前5行的工具,5個strip掃下來就可以清楚的知道G7 Targeted的狀態。
G7_50+6則是上述的G7_50(兩個strip)再加上單點CMYRGB 6個滿版狀態,也就是G7 verifier分兩個部分完成但直接在p2p上讀取,確保跟認證單位讀取同樣位置,再一次降低變數干擾。
這三個新工具就看當場的狀況來決定使用,看哪一個比較合適現場的操作。
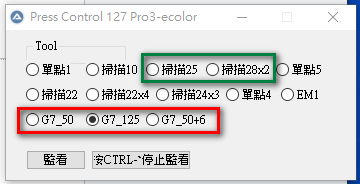
Fig. 系統工具上增加了G7_50、G7_125及G7_50+6三個工具。
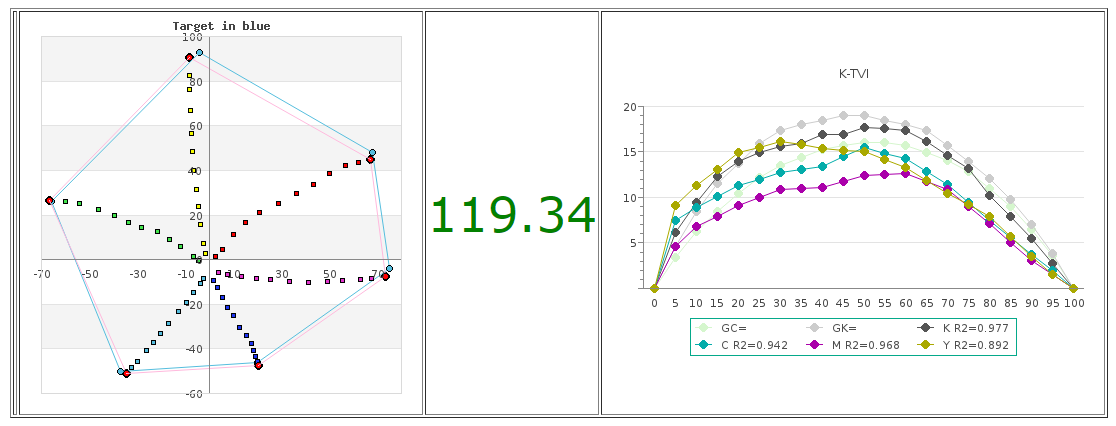
Fig. 相對於G7 verifier,G7_125工具多了CMY的版調分佈及六角圖上的階調(5%~95%)的ab值分佈。
Filed under: Uncategorized › Tags:
4 9 月, 2023 () Uncategorized › Administrator › No Comments
Low budget CMS solution.
低門檻色彩管理操作

再過兩三個星期有一個活動,對像是小型碳粉機噴墨機的租賃業者,他們通常會供應耗材(墨水、碳粉,紙張則不一定),按計數器收費,想像中這一區塊是不會去在意影像品質的。
簡單交談之後,他們不是不在意品質,而是建置成本都已經是那麼低,在知識面上、操作面上及成本面上要再加入市面上的色彩管理方案(比如i1Pro3 with i1profiler )好像不符合效應。所以,不是不在意品質,而是,如果,能有一個操作簡單、成本便宜的方案,他們是願意做的。
當然,要簡單到什麼程度、便宜到什麼程度才會是個被他們接受的solution?這個很難有明確的講法,我只就身邊的資源往這個方向設計,看能組些什麼東西出來。
第一個是測量儀器,i1 就不談了,價格超過他們的預期;目前我能找到最便宜的光譜儀就是CR30了,至於CR30的工作能力請參考之前文章。簡單講,跟i1比,絕對精度雖然不夠 ,但經由CR30數據能快速的處理掉80%的問題,還是要堪用的。
工作方法上,目前能用到最少色塊來建立icc profile 的組合是ArgyllCMS 36個RGB色塊的組合,它至少會是一個完整、沒有破損的立方體。

Fig.目前能用到最少色塊來建立icc profile 的組合是ArgyllCMS 36個RGB色塊的組合

Fig. ArgyllCMS 36格色塊組合是目前能形成完整色域空間的組合,再少一個都會破壞立方體的完整性。
操作面上也是力求單純:用CR30 經由SDK拉36個光譜值給ArgyllCMS 形成icc profile,整個程序大約三分鐘之內可以完成。

Fig. 操作介面只要輸入icc 名稱,按下監看,當偵測到有36筆資料進來的時候,會將這些資料丟給ArgyllCMS去計算icc profile。
之後將icc profile裝入系統就可以被列印驅動程序調用,來達成色彩品質控制的目的。
另從業者那邊知悉,墨水不會是原廠墨水,紙張品質也一般,就一般文具店、賣場的A4影印紙。
這樣的條件能達成什麼樣的色彩品質?
我經常用的Fogra39、CRPC6這些規格當然就用不上了,以這樣的材料品質,只能在CRPC1、2、3間找相近的規格做來源宣告;目視判斷下來,CRPC2帶出來的暗部階調更豐富些,所以這次的來源定義就把它定在CRPC2。Targeted 未必能符合,但G7 Grayscale是肯定能達成的,要不要多一個程序來達成G7 Grayscale就看業者的要求了。

Fig. icc 程序操作下來,影印紙(Plain paper)的色域介於CRPC2 與CRPC3之間,目視判定CRPC2帶出來的暗部階調更豐富些,所以Plain paper的來源定義把它定在CRPC2。
把樣本稿的色彩來源定義定在CRPC2,經由icc程序輸出之後, 這個36格的profile已能將階調值帶到位,灰平衡還差一些,最大差3.74;以這個最低階的光譜儀、最低階的耗材組合及最少格數的icc程序,能一次帶到這個位置,我認為已經很不錯了!
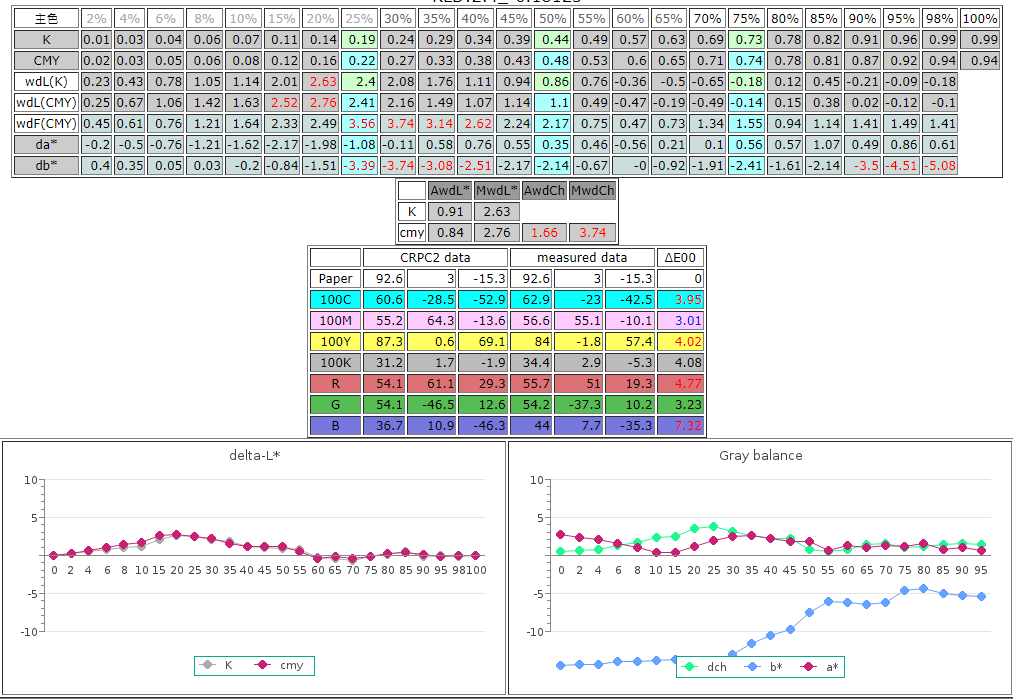
Fig. 這個36格的profile已能將階調值帶到位,灰平衡還差一些,最大差3.74;以這個最低階的光譜儀、最低階的耗材組合及最少格數等icc程序,能一次帶到這個位置,我認為已經很不錯了!
簡單修正一下Y版調就能把灰平衡也帶到位。

Fig. 簡單修正一下Y版調就能把灰平衡也帶到位。
比對一下與CRPC2 CMYRGB 六角圖,色域還不夠大,但色角度維持得還不錯。

Fig. 比對一下Plain paper 與CRPC2 CMYRGB 六角圖,色域還不夠大,但色角度維持得還不錯。
接下來處理的是,跟上一篇帖文同樣的狀況,在上篇處理模造紙印刷時,當我們符合Fogra47時,會覺得中間調太暗,圖像反差不夠,所以我們在中間調的網點擴張降了5%,同樣的,在這個Plain paper 輸出符合Grayscale的時候,也覺得中間調比較暗,所以,同樣的,在這個普通紙的程序中,一樣把50%處網點擴張降低了5%,我覺得會比較好看。

Fig. 左圖為符合Grayscale 的輸出,右為50%處網點擴張降低了5%,我認為視覺上更順眼。
總結一下,這次為小型噴墨機、碳粉機租賃業者發展的工作方案,依工作精簡程序分為幾個階段:
-
以CR30量取ArgyllCMS 36格組合形成icc profile,來源宣告設定在CRPC2即可達成G7 Grayscale 階調部分到位。灰平衡不致偏差太大,如果業者能夠接受,這是最精簡有效的工作方式。
-
我認為中間調可以再亮一點,可以改造CRPC2將它的中間調再調亮5%來作為色彩來源宣告。
-
再加入少量修正就可以讓灰平衡也能進入規範,業者必須要再多做一些教育訓練,多做幾個步驟才能達成整體灰平衡到到。
以上,小型噴墨機、碳粉機租賃業者的色彩管理工作方案大致制定下來,要再加入什麼題目,就看當天的反應狀況再來決定。

Fig. 工作成果演示:左邊為列印驅動程式將色彩管理關閉,中間為驅動程式的自動色彩校正,右邊為icc的工作方式,其版調及灰平衡的表現,還是比較優秀的
Filed under: Uncategorized › Tags:
17 8 月, 2023 () Fogra, G7 › Administrator › No Comments
自訂印刷規格 :: 曲線
Custom made printing specification :: curve

Fig. 自行定義印刷規範。
我常常在説印刷標準化就兩件事:滿版到位與中間調到位。再精簡一點,用灰平衡到位來代表CMY三個頻道中間調到位。
官方的標準,比如說Fogra39、Fogra51、CRPC6… 都有明確的滿版色彩值與版調的規定,所謂標準化,就是讓輸出的數值符合這些規則而已。
這次要來談一下,如果,現有的官方規格 無法符合我們的生產需求,我們要怎麼樣制定自己的生產標準?
再明確一點,單位裡面的模造紙印刷,按說應該依照Fogra47的規格生產,但實際的情況是,依Fogra47去生產的數位樣,在客戶端會被打槍,一個是飽和度不夠,一個是相對的中間調反差不夠,導致整體影像不被客戶接受。
從數據面上來看一下這個現象:總墨量定義,Fogra39 是300-330,Fogra47 是260。中間調定義,Fogra39 CMY 在50%處是14,Fogra47 CMY在50%處是20。紙張白度的定義相同,都是95,0,-2。
取資料集當中CMY 300的L值,Fogra39為23,Fogra47為33。C50MY40的L值,Fogra39為58.04,Fogra47為59.64。

Fig. 取資料集中Paper、CMY300與C50MY40的Lab值。
從數值上看,中間調的L值其實差不多,Fogra47實際上還亮一些,但視覺上Fogra47影像的中間調感覺上反而是比較暗的,主要是因為整體影像的最暗處Fogra39比Fogra47還低了10個L值,導致Fogra47的反差不夠,整體影像就明亮不起來。

Fig. Fogra39 與Fogra47 從最暗處(CMY300)到中間調(C50MY40)的動態範圍(Dynamic Range)。

Fig. 左邊為Fogra39的軟打樣模擬,右邊為Fogra47的軟打樣模擬。中間調的L值其實差不多,Fogra47實際上還亮一些,但視覺上Fogra47影像的中間調感覺上反而是比較暗,主要是因為Fogra47的反差不夠。
從軟打樣模擬就大概可以瞭解為什麼Fogra47的數位樣會被打槍, 客戶在做設計稿的時候,從來不會去考慮模造紙的軟打㨾模擬,應該還是以銅版紙的感覺去做稿,這直接導致了官方模造紙的數位樣不被客戶接受。
所以模造紙的生產程序從設計端的設定就是不對的,但設計師還是預期要有好看的效果。
到了我們後端實際生產的時候,照著標準官方程序會被打槍,所以我們要自行設定一個工作程序,一個脫離標準邏輯的工作程序,一個能夠更符合設計師預期的非標準工作程序。
簡單講,這個程序的預期方向是:在色彩上會比Fogra47再飽和一點,調子反差要比Fogra47再高一點,調子的感覺讓它更接近Fogra39。
有了工作方向之後就可以開始執行執行自訂規則的工作。
就像開頭講的,標準化就兩件事:滿版定義與中間調定義。
自定滿版定義的做法倒也單純:比Fogra47再多點飽和度,但不造成乾燥與背印的困擾;這就是一個自行的判斷決定。
至於版調,原則上中間50%的部分要再亮一點,亮到什麼程度自己可以決定;但至於整個版調的數值該如何Follow?這倒是一個問題。
自定義的工作程序大概是這樣子:
-
依上述,自行決定CMYK的濃度值。
-
決定滿濃度後,出不同的版調的版,用相同濃度印刷,再自行挑選認可的版調。
原則上,上述兩個動作做下來,自行定義印刷標準的工作就可以告一段落。
滿版部分沒有問題,某個濃度產生某一個色彩值,就是我們的滿版色彩標準值。
中間調部分有一個比較明確的50%的數值;那25%應該在哪裡?75%應該在哪裡?
我們可以以現在收到的數值為準,但這個數值目前包含了印機的機械變數,我們不希望這些內含機械變數的數值成為我們以後要跟隨的目標值,所以還是需要去找一個獨立的數字規則來做我們跟隨的目標,就像Fogra39 follow A曲線,Fogra47 follow C曲線一樣。

Fig. Fogra 標準版調曲線,Fogra39 走A曲線,Fogra47走C曲線。
在思考這個題目的同時,同事讓我看了這張圖,這不就是答案了嗎!

Fig. 俄羅斯網站 Msartakov 做到ISO 網點擴張近似模擬函式(msartakov approximate ISO dg function)
這個網點擴張近似函式能處理50%處擴張10%~35%之間的版調曲線,低於10%或大於35%函式就會產生錯誤。依照這一次的試驗數值,我們在50%會擴大10%左右,函式丟出來的5%階段網點擴張值如下:

Fig. msartakov approximate ISO dg function 丟出來的5%階段網點擴張值
有了這個函式下來,自定印刷規格的工作就很明確了:
-
自行定義滿版濃度/色彩。
-
自行50%處漲幅,依函式定義出其它版調的標準值。
以CT88工具帶入自行定義的標準值,我們的測試樣居然與函式值頗爲吻合;在我從事工具開發的期間,經常遇到這種視覺上的順眼,後面的數字形式也是漂亮的,這裡又是一個例子。

Fig. 我們的測試樣居然與函式值頗爲吻合
CT25 工具在25%、50%、75%的L目標值相對於Fogra39均往亮部移動,灰目標值一樣依G7規則。

Fig. CT25 工具在25%、50%、75%的L目標值相對於Fogra39均往亮部移動,25% L 值從77到79、50% L 值從58到65、75% L 值從39到46。
以上,我們制定自己的印刷規格;滿版的制定,除了要求更飽和的顏色外,須考慮到乾燥與背印的問題;中間調的制定,再決定50%的落點後,依據msartakov approximate ISO dg function 函式值來確其他網點部位的目標值。
工具上,如CT10、CT25、CT88自然依新的目標值做修定。
然後簡單的問一句:你們單位裡,是由誰來負責印刷版調的檢測與制定?如果能得到一個清楚的名字,那麼你們單位應該就沒有太大問題! 大多的時候,我是沒有答案的。
ps. 這裡的自定數值主要是公司內部的主觀認定,不同的單位,對影像的數值/品質可能會有不同的看法。
#printbynumber
#curve
#customizedSpecification
Filed under: Fogra, G7 › Tags:
17 8 月, 2023 () Uncategorized › Administrator › No Comments
系統人員工具
Tools for System administrator
在2008年底,公司在做Fogra PSO的時候,第一次清楚的感受到印刷的品質是可以完全有數字的依循,一旦工作方向能有清楚的數字依循,經由程式語言去快速的去處理這些數據及其工作意義,就變成一個很重要而且有很有價值的題目,這也是我寫工具程式的開始。

Fig.我的第一個工具,經由Xrite ColorPort 取得數據後,交由Excel Macro來處理Fogra PSO 的主色色差與版調差。因為這個工具,我們得以在稽核PSO的當下可以及時修正一個色版的錯誤而順利的取得PSO證書。
我的第一個工具程式就是經由Xrite ColorPort 取得數據後,交由Excel Macro來處理Fogra PSO 的主色色差與版調差。工具一旦形成,監看的力道就加強了許多。也因為這個工具,我們得以在稽核PSO的當下可以及時修正一個色版的錯誤而順利的取得PSO證書,而且分數還不差。
十幾年前做的東西跟現在其實沒有什麼不一樣:依數字來控制印刷品質,最多就是加個灰平衡來處理G7。
把印刷品質照顧好的邏輯其實都是一樣:把滿版(Solid)的色彩品質照顧好、把中間調(TV Tone Value)照顧好、再多加一個把灰平衡照顧好,就這樣子而已!
工具一直在演化,如前述,要處理的問題其實沒有太多不同,但計算的思考邏輯與能夠運用的資源跟先前相比,其實有很大的不同,或者說是有很大的進步。
第一個不同是現在是以光譜的概念來處理題目。有別於一開始只能依賴ColorPort導出的Lab與濃度值來處理色彩值與版調值;光譜的運算能力能處理更寬廣的問題,比如可以透過Beer’s Law去預測最佳的色度/濃度落點、在印特別色時,可以用光譜濃度的概念去更有效率的決定特別色的放墨濃度、或是在相似Lab值的K50與C50MY40的灰色塊中分辨出誰是灰?誰是K?甚至可以用SCTV的公式把光譜儀當成印版的量版器……,這些能力光靠Lab數據是算不出來的,要到光譜的層面才能處理。
再來就是取得SDK後,數據的讀取動線更加順暢,這使得操作上更加精簡,也更有效率。
然後這裡要來闡述一下,我寫的工具是誰來使用?或者是誰來執行?誰來操作?
從我的第一個工具來看,要在很短的時間知道滿版的色彩對不對?5%~95%的版調值對不對?很明顯,它不是給印刷機師傅操作的工具,它比較是給系統人員操作的工具。
對印機師傅而言,在操作的當下,他能做的,大致上就是加墨減墨而已。整體版調對不對?師傅是顧不上的。
因此,在我的工具設定裏,主要是由系統人員經由多方面的數據,建立一個良好的印刷系統交由師傅操作,師傅衹要用簡單的加減墨操作,就可以達成印刷規範的品質。
於是,我的工具,在公司系統人員的要求下,分成兩塊,一塊是給印機師傅操作、一塊是給系統人員操作,印機師傅那一塊,內容儘量簡潔,基本上呈現濃度值再加上版調值就可以了。系統人員這塊,就看系統人員想要掌握多少資訊?印機版調、印版版調(SCTV)、灰平衡修正,紙白俢正(SCCA)、數位樣狀態、軟打樣狀態、光源狀態、特別色操作、油墨品質管理、乾溼墨比較、上光/上膜數據比對補償、標準規範切換、自定標準值……但看系統人員想要掌握多少系統訊息。
若想繼續延伸,如色彩資訊與硬體參數的關聯:滾筒壓力、橡皮布壓力、硬度、水槽液電解度及pH值……。系統人員如果願意去掌握這些資訊,願意去瞭解這些數據之間的關聯,都可以把它加入系統人員這一塊。

Fig. 印機師傅工具,裡面祇有簡單的選項。

Fig. 印機師傅工具,只呈現濃度值及版調值。
Fig. 系統人員工具,這就看系統人員願意去掌握多少系統資訊。

Fig. 一張A4裡面幾個簡單的導具已經足夠系統人員去掌握印刷系統的狀態。要取得Fogra PSO 或Idealliance G7,這裡面的導具已經足以實現。
這裡再多說明一下系統人員工具的內容:
-
CT10,這是一個能最快速的知道系統狀態的工具,可以很快的知道滿版色對不對?也可以很快的知道怎麼樣去調整滿版色的濃度才能達到最好的色彩值。這裡也可以很快知道四座色墨網點擴張的狀態對不對?再來就是,可以很快的知道灰平衡對不對?如果不對,也能提供清楚的調整方向。

Fig. 可以很快的知道滿版色對不對?四座色墨網點擴張的狀態對不對?灰平衡對不對?
這個導具照說應該可以交給印機師傅使用,就我手邊的單位,會去使用的師傅還是偏少,但用上了就不會再回頭用單點,效能上差太多了。


Fig. CT10 的進化,上圖是舊版,下圖是新版。新版確保相臨色差在de20以上,這樣的導具在Strip Reading 可以不必經由斑馬線導尺。控墨臺上少一件東西,就是對師傅操作的多一份友善。
-
CT22,主要是用來讀取版調,印機版調或印版版調都可以讀取。印刷版調的結果是印版版調與印機版調共同堆積出來的,是有必要兩邊的數據都必須掌握到。

Fig. 以i1讀取印版版調

Fig. CT22 版調工具,印版版調或印機版調皆可讀取。
-
CT25,CT10 再加入RGB及25%與75%的階調及灰平衡,gmi及中國C9也是用同様的組合來做評分。我的工具除了評分之外,再加入三點(25%,50%,75%)灰平衡修正,這個三點曲線修正,已具備G7 grayscale的能力,配合適合的紙張與放墨,G7 Targeted 一樣能到位。

Fig. CT25 工具
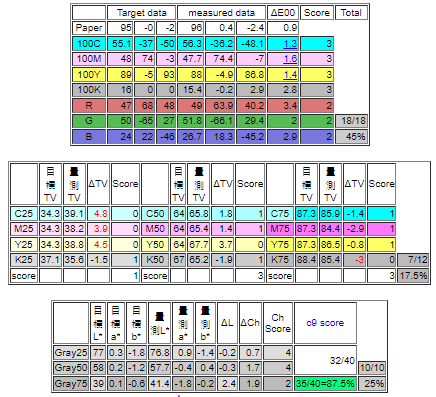
Fig. CT25評分工具。

Fig. CT25 三點灰階修正工具。

Fig.三點灰階修正有多種工作方式,其中之一為photoshop acv 曲綫修正,只要將acv應用到圖檔,再次輸出即可將該影像帶入Grayscale 範圍。
-
CT88(4×22),這個工具讓系統人員很快的瞭解到4個色座的版調狀況,相對之前的CT10、CT25,這裡以5%的精度去觀察版調的變化,在這裡可以掌握最完整的版調變化,對公司來講,一個月應該至少看一次這個圖表,aq確認機器狀況都有在正確的位置。

Fig. 這個CT88(4×22)是從CT84(4×21)演化而來,在原本5%的基礎上,加入了2%的取樣點,用來評估印版能否表現最小的網點。再犧牲了Y40的樣本點,塞入了C50MY40灰平衡參考點,讓CT88的評估性能更加完整。

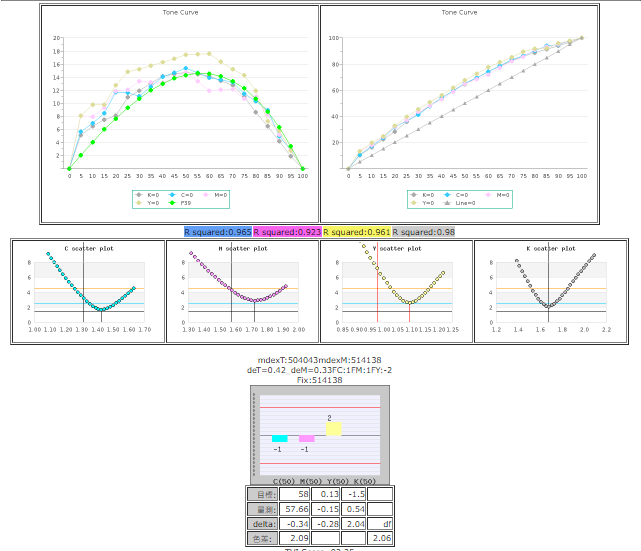
Fig. CT88提供最完整的版調觀察。
-
CT56(2×28),基本上與Curve4 G7 Verifier一模一樣,衹是用自己的程式碼把它實現一遍。

Fig. CT56(2×28)導具,它就是G7 Verifier。


Fig. CT56(2×28),基本上與Curve4 G7 Verifier一模一樣,但多加3點灰階修正功能。
以上,先介紹了5個系統人員區塊的工具。系統人員該去瞭解的事物應不止於上述5個功能,但如果能理解並能去操作上述的5種功能,基本上,公司 對於印刷品質的掌握應該都有80分以上了。
能對印刷品產生變數的地方非常的多,實施印刷標準化,衹是建立一個好的基礎去應對各式各樣的問題。
這裡舉一個例子來說明印刷品一旦脫離標準狀況,它帶來了什麼樣的問題,以及我們怎麼去應對處理?
我們以CRPC6出某一包裝的數位樣,但實際印刷的白卡與CRPC6的紙白差了4個de00以上(較黃),這導致師傅在印刷時無法跟上數位樣。
系統人員介入的方式是:做出一個以白卡修正的SCCA資料集,以此產生profile做為數位樣的目標值,師傅跟著新的數位樣操作就沒有問題了。
工具的運作概念是:在系統工具輸入紙白Lab,系統會丟出一個SCCA修正過的icc profile。系統人員將新的profile導入rip作為目標值,新的數位樣師傅就很好跟了。

Fig. 以CRPC6出某一包裝的數位樣,但實際印刷的白卡與CRPC6的紙白差了4個de00以上(較黃),這導致師傅在印刷時無法跟上數位樣。
再丟一個脫離標準化的例子,客戶看樣時只在意臉龐的膚色是不是她心裡要的那個樣子!對產品主色系色差(橘色)倒是沒那麼在意,那也就這樣子吧!

Fig. 客戶看樣時只在意臉龐的膚色是不是她心裡要的那個樣子!對產品主色系色差(橘色)倒是沒那麼在意。
印刷標準化是建立一個好的基礎,並不代表能夠解決所有的問題;重要的是,這個好的基礎,可以幫助更快處理遇到的問題。
數據工具的使用不只是在維持品質,更重要的是以數據來找出問題,並且能以數據去解決問題。
#printbynumber
Filed under: Uncategorized › Tags:
5 7 月, 2023 () 色彩管理 › Administrator › No Comments
The application of the phone colorimeter: printer profiling
繼上篇將手機作為色度計,這次來探討一個應用:用手機來做printer profile。
工作程序/邏輯
- 用手機拍攝導具。左邊為標準稿,36個Lab值已由i1Pro3量取,以CGATS 文字檔格式儲存。右邊為新的印表機印出來的導具,剪下來放在標準導具旁邊。拍攝時注意一下不要被影子擋到。

- 先手動裁切左邊與右邊兩個圖檔,左邊為標準稿,右邊為樣本稿。

- 開啟程式,分別調入標圖稿、標準稿數據及樣本稿。
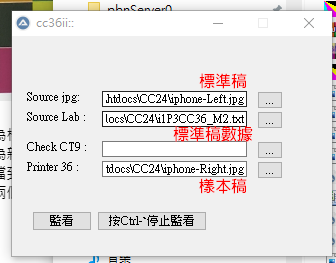
- 啟動程式。整個程式運作可參考此影片
https://www.facebook.com/reel/2098081573924303
https://youtu.be/pX5Wrg1OnwY
程式內容動作說明
- 計算標準圖稿6×6中心位置,取3×3 pixel RGB 平均值,這裏會經過36個程序,把這36個位置的RGB值找出來。
- 取完36組RGB後合併標準稿Lab數據爲CGATS格式以供ArgyllCMS計算使用。
- 調出ArgyllCMS 指令,開始計算 camera profile
- 程式會接著計算camera profile 精度。本次示範profile精度為0.45de00(36組de00平均值)。
- 接著開始處理 printer profile,同上述邏輯,計算右邊樣本圖稿6×6中心位置,取3×3 pixel RGB 平均值。
- 取得的36組RGB值,透過已生成的camera profile 可取得36組Lab
- 將此36組Lab關聯到印表機導具的36組RGB定義即可由ArgyllCMS產生 RGB printer profile.
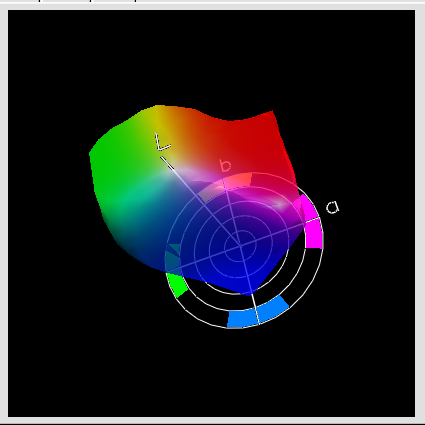
Fig. phone colorimeter Camera profile

Fig.phone colorimeter Printer profile

Fig. phone colorimeter 產生的printer profile也可以有不錯的效果。左邊為生產單位在用的數位樣,右邊為phone camera得出來的是數位樣,在色彩及調子上沒有差太多,數據我就不po了,外觀是還不錯的,就是,有被管理過的樣子。
====================================================================
這衹是我手邊眾多想去探索的題目的其中一個。用手邊最簡單的設備,將色彩現象變成數字,然後再去進行操作與管理。以這個案例而言,確實有達到我預期的效果。
這個案例的基本邏輯是:手邊先具備標準稿及其數據。所要處理的色彩題目可以透過參照標準稿的相對反應來取得其色彩數值,進而達成以數字去處理色彩的目的。
數字精度當然還不是那麼好,但起碼用數字的方式來操作色彩的目的是達成了。
要形成一個APP還有段距離,但基本工作邏輯沒問題,也確實有達到效果。
依此邏輯看看能發展到什麼程度?想像以後衹要身邊帶著標準稿,就可以去操作一些色彩的題目!比如說用手機去判定印刷品的色彩品質好不好?用手機去判定顯示器的色彩品質好不好?題目先想著,什麼時候要去處理這些題目就再說了!
Filed under: 色彩管理 › Tags:
5 7 月, 2023 () 色彩管理 › Administrator › No Comments
Phone camera as colorimeter?

我一直在說,在色彩的工作上需要一個儀器將色彩這個現象變成數字,而這個所謂的儀器,最低階的架構會是什麼樣呢?
目前手上,所謂低階的色度儀器是上圖那兩顆。
還有更低的嗎?其實,手機相機就是RGB sensor,能拉得到數值,能取得數值,就有機會可以成為色度計。
這一篇就是這一方面的探索。
先把工作方法、工作邏輯先理出來,將來是否能夠實際運用?運用的場景?……都會建立在這一次探索的基礎上。
工作邏輯其實很單純:
相機做為一個RGB sensor,大量比對相機RGB的數值與實際色彩Lab的數值,就能建立起一個相機RGB與實際色彩Lab的對應表(icc profile)。如此,相機的RGB反應值就可以透過此對應表得到一個Lab數值。也就是,相機RGB透過一個profile,它就可以是一個色度計。
邏輯已經有了。工作方法上要處理哪些問題?程序如何進行:
1.樣本量:相機取色塊樣本自然不是問題,再多色塊都是一個shot,問題是,要比對的色彩數值必須一個一個的量出來;用i1來量,取一個A4面積400個樣本不是太大問題,如果用單點設備來量,這個工作量就有點大了;基於上面幾次的發文,36個色塊已經足以建構一個完整的profile;同樣的,基於最少的工作量,這次一樣用36個樣本來建立相機的profile。
- 建立一套程序來取得相片裡面36組RGB數值,這一次用imagemagick來處理這方面的作業。程序如下:
- 先自行把作業範圍crop下來。
- 以imagemagick 指令’convert -info:’取得圖像長寬 pixel 數。
- 依上述長寬pixel計算6×6的中心點位置。

- 依上述36組RGB值與實體36組Lab值即可形成icc profile。
數值驗證:
將36組相機RGB數值經由profile取得36組Lab值,與原始Lab值比對色差,得結果如下:
左邊一組為以 percetual intent 計算Lab,與原始Lab比對,平均de00色差0.8,最大色差2.3。右邊一組為以 absolut intent 計算Lab,與原始Lab比對,平均de00色差0.59,最大色差1.88。
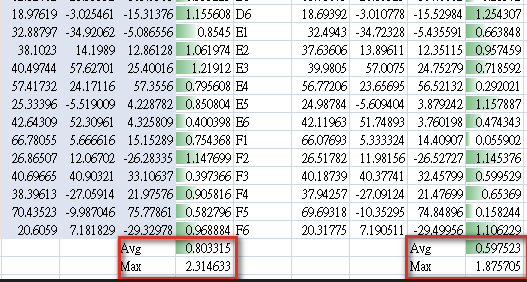
簡單結論
這一次工作邏輯及工作方法探索的結果,相機RGB sensor 數值經由轉換可達到平均精度0.5的位置。回應到本篇的主題,手機相機是有能力達成色度計的功能。
當然,實際使用上還是會有一些問題,比如說相機上下左右曝光的均勻度就是一個問題,這方面的工作邏輯也有做一些探討。
相機曝光均勻度補償的工作邏輯如下:
- 先取得上下左右4個白色部分的RGB值。
- 取其平均值作為參考亮度。
- 以上述平均亮度為目標,取得6×6 36個位置的補償因子(compansate factor)。

Fig. 左邊為原始曝光,右邊為曝光均勻度補償結果。
- 將前一階段取得的6×6 36組RGB,依補償因子算出新的RGB數值,此數值即為曝光平均度矯正後的數字。
所以就是用軟體的方式來補足曝光均勻度的問題。
以上兩個邏輯堆疊在一起。增加了相機作為色度計的信任度。
我先完成這兩個邏輯,後續再來看看怎麼應對工作場合中的變數。
#PrintByNumber
#colorimeter
#CameraAsColorimeter
Filed under: 色彩管理 › Tags:
