14 3 月, 2023 › Fogra, 印刷標準化 › Administrator › no comments ›
Establishing a new work model.
建立新的工作模型
一直以來,我都是用i1加sdk來處理刷印刷上的作業跟檢測,很有效率也還算方便,但i1必須經由usb線掛到電腦(筆電)上才能作業,有時候要做一些快速的demo或快速的講解時還是有點麻煩;最近陸續接觸到了一些經由藍牙與手機連線的色度計/光譜儀,就數據的擷取上,是要比 i1 + usb + 筆電 方便多了。先撇開這些儀器的數值精度,我在i1/sdk 發展的數值邏輯/工作方法是可以完全套用過來的。
這次試著將我最經常使用的CT10工具轉到手機的模式來工作,手機與筆電的表現方式還是有所差異,加上我手機程式的能力還在相當的初階,只能粗暴的堆積我所知有限的程式元件,勉強做出一個可用的版本。

Fig. 超過5000行程式碼的暴力堆積,勉強做出一個可用的工作模型。
這裡就簡單介紹一下目前手機APP上能呈現的功能。

數值擷取後,分兩個層面來運用這些數字。
第一層是印刷品質的評分;根據滿版的數值、50%版調的數值與灰平衡的數值來對成品作出評分。

Fig. 主畫面會呈現10個色塊的Lab值與濃度值;對於中間調色塊還會呈現其版調值。
評分部分目前放出三個印刷規格的選項,分別是 Fogra39、Fogra51與CRPC6。由下圖中數據顯示,同一組數據,在Fogra39與CRPC6之間的差異可達到6分。滿版的目標值其實差異不大,主要是TV目標值差異比較大,CRPC6在50%的CMYK TV增值比Fogra39都要大上2%。

Fig. 目前提供三種印刷規範的目標值依据,分別是Fogra39、Fogra51與CRPC6。
在主畫面的數據基礎上,再下一層的功能是帶出操作指令。衹要點選主畫面的色塊部分就會帶出該色塊相對應的操作指令。

以上圖為例,C墨的操作畫面顯示目前濃度1.45,色差6.12,當濃度降到1.21時,色差會降到2.81,所以操作指令就是降墨0.24。在整個顯示系統上,當數值不在寬容範圍內時,會鋪上紅底警示,所以操作的動作就是運作到不要出現紅色色塊為止。操作直覺,判讀迅速。
M墨的操作指令畫面顯示目前濃度1.59,色差5.37,當濃度降到1.34時,色差會降到2.1,所以操作指令就是降墨0.25。

Y墨操作畫面顯示目前色差4.76,最佳的色差預測也只到4.72,由此兩個紅底訊息顯示該黃色油墨不可能操作到合格範圍,只能更換油墨再做嘗試,要不然最多只能操作到色差4.72。
K墨操作畫面則顯示已經進入合格範圍,再加0.15濃度的話,色差可從2.84降到1.08。
點入灰色色塊,畫面中的紅色警示顯示L少了4.46,灰差倒是還好,祇有1.35,操作指令則為C -3、M-5、Y-4,照著操作,就可以把灰平衡拉到更好的位置。

以上,經由簡單的手機APP操作,可以很快的知道印刷品質的好壞,也可以引導出更好的操作方向。
第一層的分數功能可以是印刷品買家對產品的驗收依據,可以是品管部門的內部控管依據,當然也可以是印刷部門的自我控管。
這一層的功能,也用來讓印刷買家對生產單位施加標準化的壓力,促使生產單位做出標準化的產品。
第二層的功能明確的指引印機師傅將機器操作到更好的位置。生產單位也可以依此數據來保障自己的生產品質,而不是一味的去迎合客戶不合理的喜好與要求。
經由此工作模型,可以更方便、更快速的將印刷標準化的作業概念施行到這個產業。隨著建置與操作門檻的降低,可以讓產業裏更多的人進入數字的領域。
基本工作架構的模型已經建成,是實際可行的。在觀念上,我更重視的灰平衡操作(相對於滿版的絕對色彩值操作)是一種相對操作的概念(灰平衡目標值是相對於紙張而來)。這種相對操作的情境對儀器絕對精度的要求就沒那麼高了,衹要求儀器表現穩定就可以了。
市場對品質的要求有高有低,對高品質的追求永遠是一個努力的方向。但找出一個能夠迅速有效的滿足80%品質市場的工作方法,也是一個值得去努力的方向。
基礎工作模型已經完成,之後期待的是:
*精度更好,更負擔得起(afordable)的儀器。
*具掃描能力(strip reading),能夠更快速的收集更多的數據。
*再來就是對數據的應用還是有很多的想像,比如經由機器學習來優化儀器的數值、經由數據Ai來預測客戶對色彩與品質偏好、經由數據來監測與管理整個印刷系統的狀況是否建全……。
對我來說,要做的題目還有很多 ,我也不知道何時才能起到些什麼作用?李鴻章說一代人做一代事,我說一類的人就做一類的事,該做的事,做就是了!
Tags: cr30
14 3 月, 2023 › Fogra, G7 › Administrator › no comments ›
Establishing a new work model.
For a long time, I have been using i1 with SDK to handle printing tasks and inspections. It was very efficient and convenient, but i1 had to be connected to the computer (laptop) via a USB cable to function. Recently, I have come into contact with some colorimeters/spectrometers that can connect to the phone via Bluetooth. In terms of data acquisition, it is much more convenient than i1+USB+laptop. Setting aside the accuracy of these instruments, the numerical logic and working methods developed in i1/SDK can be completely applied to them.
This time, I tried to switch my most frequently used CT10 tool to work in mobile mode. However, there are still differences in performance between the mobile phone and laptop, and my mobile program skills are still quite basic. I could only crudely stack the limited programming components I knew and barely create a usable version.
"Fig. A brute-force stack of code exceeding 5000 lines, barely creating a usable working model.
Here, let me briefly introduce the functions currently available on the mobile app.
After capturing the numerical values, these numbers are applied on two levels.
The first level is print quality scoring, which evaluates the finished product based on the solid CMYK color value, 50% tone value, and gray balance value."
Fig. The main screen displays the Lab values and density values of 10 color patches. For the 50% color blocks, the tone value is also displayed.
For the scoring section, three printing specification options are currently available: Fogra39, Fogra51, and CRPC6. As shown in the data in the following figure, the difference between Fogra39 and CRPC6 can reach up to 6 points for the same set of data. The target values for the solid CMYK are not significantly different, but the TV target values differ greatly, with CRPC6 having a 2% higher increase in CMYK TV at 50% than Fogra39."
Fig. The current version provides target values based on three printing standards: Fogra39, Fogra51, and CRPC6.
Based on the data displayed on the main screen, the next layer of functionality is to provide operational instructions. Simply clicking on a color patch on the main screen will bring up the corresponding operational instructions for that color patch.
As an example using the figure above, the operational screen for C ink shows a current density of 1.45 and a color difference of 6.12. When the density is reduced to 1.21, the color difference will decrease to 2.81, so the operational instruction is to reduce the ink by 0.24. Throughout the display system, when values are not within a tolerant range, a red background warning will be displayed , so the operation is to work until there is no red color block. The operation is intuitive and the interpretation is fast
The operational instruction screen for M ink shows a current density of 1.59 and a color difference of 5.37. When the density is reduced to 1.34, the color difference will decrease to 2.1, so the operational instruction is to reduce the ink by 0.25.
Y ink operation screen shows a current color difference of 4.76, and the best color difference prediction is only up to 4.72. Therefore, two red block messages indicate that the yellow ink cannot be operated within the acceptable range, and only by replacing the ink can it be attempted. Otherwise, it can only be operated up to a color difference of 4.72.
The K ink operation screen shows that it has entered the acceptable range, and if the density is increased by 0.15, the color difference can be reduced from 2.84 to 1.08.
Clicking on the gray color patch, the red warning on the screen shows that L is less by 4.46, but the gray difference is okay, only 1.35. The operation instructions are C-3, M-5, Y-4. By following the instructions, the gray balance can be improved.
The above content explains that with the help of a simple mobile app, it is possible to quickly determine the quality of printing and guide towards better operational directions.
The scoring function of the first layer can be used as an acceptance criterion for print buyers or an internal control standard for the quality control department. It can also be used for self-control of the printing department.
This layer’s function is also used to put standardized pressure on the production unit and encourage it to produce standardized products.
The second layer provides clear guidance to the printer on how to operate the machine into a better position. Production units can also use this data to ensure their production quality, rather than blindly catering to customers’ unreasonable preferences and requirements.
With this working model, it is easier and faster to implement the concept of printing standardization in this industry. As the threshold for building and operating the system is lowered, more people in the industry can enter the digital domain.
The basic working model has been established and is feasible in practice. In terms of concept, the gray balance operation (relative to absolute color value operation for solid color) is a relative operation concept (gray balance target value is relative to the paper). This relative operation context does not require high absolute accuracy from the instrument but only requires instrument stability.
The market demand for quality varies, and the pursuit of high quality is always a direction worth striving for. However, finding a work method that can quickly and effectively meet the quality demands of 80% of the market is also a direction worth striving for.
The basic working model has already been completed, and what is expected in the future is:
-
More accurate and affordable instruments.
-
Instruments with scanning capabilities (strip reading) to collect more data faster.
-
There are still many possible applications of the data, such as optimizing instrument values through machine learning, predicting customer color and quality preferences through data AI, and monitoring and managing the entire printing system through databases.
For me, there are still many things to do, and I don’t know when I will be able to make a difference. Li Hongzhang said that one generation should do one generation’s work, but I say that one type of person should do one type of work. I will just do what I need to do!
23 2 月, 2023 › Uncategorized › Administrator › no comments ›
CT25 on duty : G7 certificate & proof correction


Fig.CT10 at work
CT10 是給師傅最常用的工具,一次十格色塊的掃描就可以知道满版狀況、中間調狀況及灰平衡狀況。師傅可以依數据狀況推定下墨指令,看是要維持滿版到位或是灰平衡到位,還可以查覺到網點擴張是否異常, 若是脫離正常狀況太多,就必須要求系統介入處理。CT10工具的重點在於提供最單純加減墨的指令,透過加減墨就可以維持印刷品質達到一個可被接受程度。

CT25 在CT10的基礎上加入了25%及75%的資訊。多了這兩段的資訊,足以用來建立一個健全的印刷系統,用它來取得G7認證,當在能力之間。
G7 certificate
這一次的G7續証,不從1:1線性版開始,直接用現行曲線開印,想著是不是可以偷點時間,偷點程序。
程序邏輯一樣是先確認滿版放墨,再來修正版調及灰平衡。
工具:i1 Pro3,CT25、CT28x2(G7 Verifier)
先確定CMYK放墨OK,RGB也都在寬容值內。此時Gray50及Gray75尚未達標。

Fig. 第1個步驟是CMYK主色的滿版預測,Beer’s Law 在這個地方有很好的預測能力。
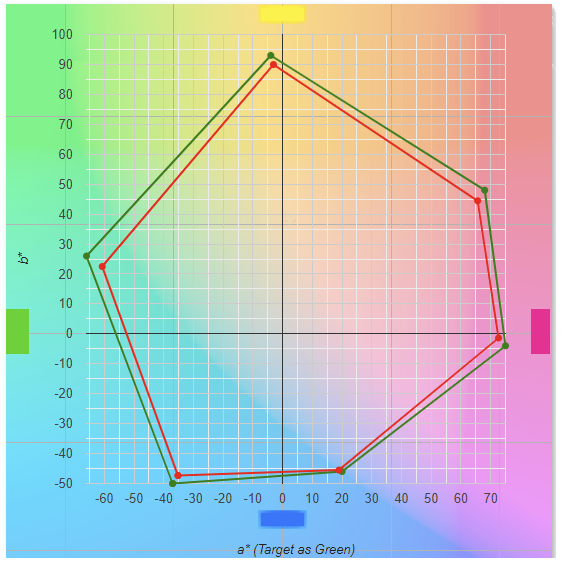
Fig.再下來就是用6角圖來推算RGB的落點。
調整到CMYKRGB都到位置之後。版調及灰平衡交給CTP補償就行了。

Fig. CMYKRGB 到位,灰平衡尚未到位。
CT28x2顯示最大K 亮度差超標(>3.0),平均灰差超標(>1.5)。

Fig. 以CT28x2檢測Grayscale,灰平衡平均值尚未到位。
依据CT25做了25%、50%、75%做三點修正。

Fig. 取得 CT25 3 點修正資料。

Fig. CT25 3點修正,從現行版補償修正,不是從1:1線性版修正。
修正後G7 Targeted 達標。

Fig. CTP 3點修正後,以CT28x2工具確認,已能達到 G7 Targeted 到位。

Fig 印樣送認證單位,確定取得認證,顯示CT25工具提供的三點修正能力確實有其效果。
綜合CT25工方法:
1. 先決定CMYKRGB到位
2. 取得三點修正值
3. 重出CTP
4. 以 CT28x2 工具驗証
相對於 PressSign+Curve4 作業,確實節省許多工作時間及建置成本。


======================================================================
這次在時間、程序算是有偷到。不過話説回來,平時確實的保養機器,隨時隨地的去關注數據,應該要能夠隨時都能達標,用不著這再一次的3點修正。
印刷標準化的概念在整個業界應該要形成一個普遍的共識,礙於知識門檻,技術門檻,及建置門檻,還是有很多廠(及其從業人員)並沒有進入到印刷標準化及數據化的領域。
pressSign、Curve4 這類的產品在業界已行之有年,自有其Brand name 印象,對一些具規模的大廠,直接使用有Brand name的產品,可以減少信認疑慮。
回到數據本身,數據本身並不需要一個品牌,只要數據對了,就是對了。
CT25提供一個進入印刷標準化的一個備選方案(alternative option)。幾乎是最低的知識門檻、技術門檻與建置門檻。一些還沒建立系統的廠家,可以嘗試看看。
花兩個鐘頭把程序跑一趟,就可以很清楚知道數據運作是怎麼回事。相對於G7認證,CT25作業不是一年只做一次的認証,而是日常的操作。
數據不一定能解決所有的問題,因為客戶不見得會跟你跑數據;但把數據能力建立起來,處理問題的觀點會不一樣,處理問題的方法會更多元、更明確。
======================================================================
再介紹一下CT25在數位打樣的工作方法。這是一個非原廠墨水的原紙打樣系統,沒有期待一定要符合Fogra 或CRPC的打樣標準,但至少要符合C9的要求。
左邊樣張50%及75%的灰平衡並不符合要求,經過一次CT25的三點修正。右邊那張的灰平衡已能完全符合C9或是gmi要求。
同樣的,這是一個很快速的處理方法,而且達到有效的數值。
Fig. 左邊為修正前狀況,因灰色偏差,pbn分數系統取得77.78。右為CT25 3點修正結果,分數為95.37。
23 2 月, 2023 › Uncategorized › Administrator › no comments ›
New Tool : 3 Points Gray approaching
3點灰色修正工具。
在CT25工具裡,已經有3點(25%、50%、75%)灰色修正這個功能,不同的是, CT25的3個灰色目標值是根據G7規則而來,也就是隨著紙張的顏色而變動,而這個工具的三階段灰是自行定義,不走G7規則。
為什麼要做這個自定義灰目標工具?
其實想做這個工具已經很久了!印刷標準化有它一套規則,但現場有太多狀況不是在標準化的架構裡面。
先提一個例子:

客戶拿著別家廠印好的盒子,要我們照著印就是。
那個"別家廠"的印刷規範是怎麼樣?完全沒有頭緒;用我們設定好的數位樣去比對,就已經差很多了!
這個案子勢必是要用脫離標準化的方式去執行!
但脫離標準化就沒有規範了嗎?就衹能讓師傅自主發揮了嗎?
再一個例子:

數位樣依CRPC6標準輸出,標準紙白是95,1,-4,實際生產紙張的紙白是94.8,2.6,-9.1。灰25%的b值在標準樣張上是(-4*0.75=-3);若依G7規則(CT25工具邏輯),印刷成品上灰25%的b值要在(-9.1*0.75=-6.8);因紙張上的差異,光b值就要差到3.8,視覺上已經不能接受了。
以上兩個例子都是脫離標準化架構的工作案例。
所以,這個工具的重點在於自己定義灰目標,大致上就是分:亮部、中間調與暗部(hilight、midtone、shadow)三個灰色參考點,不一定要限制在25%、50%、75%三個精確定義的灰色塊上。就像第一個例子,樣品上沒有色塊參考點,衹要能在樣本上找到三階段參考灰即可。
工具使用邏輯:
1. 在樣本上取得亮部、中間調、暗部三個參考灰(reference gray)做為目標灰。
2. 在印刷品上取得同樣位置亮部、中間調、暗部三個參考灰。
3. 依循亮部、中間調、暗部三個GrayFinder邏輯,可以取得亮部、中間調、暗部三組CMY修正值。
4. 取得三組CMY修正值之後,可以修圖,也可以修版,都可以讓三個印刷灰能追得上目標灰。
對這種異常的案子,建議用修圖的方式把案子處理掉就好,不需要為這些異常的案子來改變現行運作的印刷系統。
實驗案例說明:

中間一張為某個無法確定印刷規範的印樣(目標印樣),左邊一張為現行的生產方式(生產印樣)。最右邊為依目標印樣與生產印樣3點灰色修正後的印樣(修正印樣)。
從數據上看會更具體一些。
L1,a1,b1 為目標灰值,L2,a2,b2為生產灰值,25%,50%,75%的灰差為3.51, 6.01, 4.4。建議修正值為CMY25(-3, 0, +2),CMY50(-5, -1.5, +5),CMY75(-2, -1.5, +5)。

修正後的灰差為:1.38(25%)、0.96(50%)、1.08(75%)。數值上顯示出這是有效的修正。視覺上也是呈現有效的修正。
在正常的,標準化的工作架構裡,CT25已經有能力去操作出G7 targeted的規範。但遇到一些非標準化的印件,CT25能找出問題,但不見得能解決問題。
相對起來,自定義3點灰階修正還比較能具體的去處理問題,操作起來也相對便捷,量測三個目標灰,比對三個生產灰,6個單點click就可以取得有效的工作指令。
#printbynumber
#thePowerOfMakingYourOwnTool
Tags: grayfinder
1 1 月, 2023 › Uncategorized › Administrator › no comments ›
通過機器學習減少數據差異
Reduce data discrepancies via machine learning

手邊越來越多測量色彩的儀器,量測出來的數值都不太一樣,這個"不一樣"是可以理解的:不同的感應元件、不同的物理結構、不同的校正邏輯、不同的優化演算,得到的數值不同可以理解。但差異要在多少之內才算堪用?即使是臺幣20萬以上的儀器,還是會有一個de00的差距;那這些祇有幾千塊的儀器,我們能有多少期待?
當然不會期待這些低階的儀器拿來做Fogra、G7、gmi這類的認證;但作為一個將色彩感官導入為數值概念的這樣一個敲門磚的性質,我一樣認可這些低階的設備。
對於這些敲門磚性質、低階儀器的精准度,我認為兩個de00 是堪用的。
對於這些低階儀器的運用,更重要的是想法的轉變:色彩這一個主觀的感受,經由儀器,色彩會是一個清楚的數字;一旦是數字,我們在驗收或是操作控制上,都能有更好的掌握。對於這些低階的儀器精準度,即使只帶到兩個de00的位置,我還是持正面的態度。再強調一次,對於這些會拿儀器來看待色彩的使用者,有能力或者有意願將色彩當成數字來處理的人,思考模式的轉變、才是最重要的意義。
以下數據是以 Fogra media wedge CMYK V3(72格)取樣,某低階儀器相對於i1Pro3差異為最大1.79de00,平均0.91de00。我認為這樣的敲門磚算是堪用了。

Fig. 以Fogra media wedge CMYK V3(72格)取樣,某低階儀器相對於i1Pro3差異為:最大1.79de00,平均0.91de00。
除了準度夠不夠好,另一個想法是:這個色彩現象現在已經是一個數字,一旦是數字,我們就可以透過一些數學(統計學)程序來優化這些數字,讓儀器之間呈現的數值可以更接近。不管低階高階,對我來説,是有必要去找一個工作程序,讓兩個儀器的數字更接近。
最近接觸到 Machine learning,就試試其中幾個工具,看能不能達成預期的效果。

Fig. python machine learning 工具
稍微瞭解一下 python machine learning 的功能,看來是很多統計學的工具庫,主要是在調用上顯得方便零活許多。內容很多,需要一些時間去消化理解。這次先試試 Multiple Regression 看看能有什麼成果。
首先,要怎麼餵資料就是一門學問:要多少樣本數?色彩樣本的分佈情況?樣本的參考點要設多少個?怎麼設?
一方面要增加精度、一方面又要讓操作儘量精簡;各種方面的考慮需要不斷的Trial and error去找到最佳的組合。

Fig. Fogra media wedge CMYK V3
這一次用Fogra media wedge CMYK V3(72格)取樣,以i1 Pro3 的數值做為目標組,CR30的數值做為實驗組,如上圖所示,72個數據下來,最大差異1.79de00,平均差異0.91de00。
試著用multiple regression 做兩組數據間的關聯;分別試了一次方的關聯與三次方的關聯,結果如下:
72個訓練樣本,一次方(degree=1)、三個變項(L,a,b)關聯,
由machine learning 得出來的關聯式如下:
L(predict)=-0.6322502637360+1.02341127*L(measured)+0.01230391*a(measured)-0.00582456*b(measured)
a(predict)=-0.5175238518122+0.00349049*L(measured)+1.00839398*a(measured)-0.00698096*b(measured)
b(predict)=0.6629766575213-0.01703327*L(measured)-0.01942645*a(measured)+1.00670896*b(measured)
經由關聯式修正CR30量測值,與i1Pro3的最大差距由1.79 de00 降到 1.57 de00,平均差距由0.91 降到 0.45 de00,算是有効的訓練。

Fig. 72個訓練樣本,一次方(degree=1)、三個變項(L,a,b)關聯,最大差距 1.576 de00,平均差距 0.445 de00
試著用三次方(degree=3)三個變項(L,a,b)關聯
由於machine learning 得出來的關聯式過於複雜,用程式代碼來代表一下。
三個變項、三次方關聯序:
‘l’, ‘a’, ‘b’, ‘l^2’, ‘l a’, ‘l b’, ‘a^2’, ‘a b’, ‘b^2’, ‘l^3’, ‘l^2 a’, ‘l^2 b’, ‘l a^2’, ‘l a b’, ‘l b^2’, ‘a^3’, ‘a^2 b’, ‘a b^2’, ‘b^3’
共19項。
程序碼如下:
Predict = intercept +regression_model.coef_[1]*mL+regression_model.coef_[2]*ma+regression_model.coef_[3]*mb+regression_model.coef_[4]*pow(mL,2)+regression_model.coef_[5]*mL*ma+regression_model.coef_[6]*mL*mb+regression_model.coef_[7]*pow(ma,2)+regression_model.coef_[8]*ma*mb+regression_model.coef_[9]*pow(mb,2)++regression_model.coef_[10]*pow(mL,3)++regression_model.coef_[11]*pow(mL,2)*ma+regression_model.coef_[12]*pow(mL,2)*mb++regression_model.coef_[13]*mL*pow(ma,2)+regression_model.coef_[14]*mL*ma*mb++regression_model.coef_[15]*mL*pow(mb,2)+regression_model.coef_[16]*pow(ma,3)+regression_model.coef_[17]*pow(ma,2)*mb+regression_model.coef_[18]*ma*pow(mb,2)+regression_model.coef_[19]*pow(mb,3)
L intercept = -3.3311399027457753
L coefficients = [1.17959558e+00,1.51891147e-02,1.67282780e-02,-2.49762450e-03,-1.09825293e-04,-1.09264761e-03,-1.50801917e-04,-2.44847912e-04,6.39178595e-04,1.17880166e-05,-5.01404941e-07,1.11556891e-05,2.25110985e-06,6.49420255e-06,-1.11279844e-05,1.39766751e-06,-6.58363756e-07,-3.61386136e-06,2.77494282e-06]
a intercept = 0.3279017535550137
a coefficients = [-3.31344905e-02,1.08827162e+00,1.32214608e-03,5.74573847e-04,-2.14549183e-03,-3.29938673e-04,-1.10366977e-03,-1.52137755e-04,4.83060199e-05,-3.00381953e-06,1.08584656e-05,2.18611803e-06,1.55290706e-05,3.73154456e-06,5.74063836e-07,1.41496091e-06,2.62797607e-06,-9.81271691e-07,1.41858407e-07]
b intercept = 0.08716778562166638
b coefficients = [5.57303728e-03,-6.06917904e-02,1.07554181e+00,-4.97617821e-04,2.19794160e-03,-7.81213339e-04,5.98329555e-04,-2.34457666e-04,7.51041096e-04,3.71288376e-06,-1.94526634e-05,-1.63889837e-06,-8.64799163e-06,-3.87728970e-06,-3.76102212e-06,-4.37681031e-06,-1.17723242e-05,-2.55467020e-06,-5.85244726e-06]
三個變項,三個次方的關聯,產生多達19個迴歸係數;如此龐大的計算量,在 python sklearn 套件裏,排除掉資料宣告,只要三個敍述就可得出預測關聯式。套件的使用非常方便,重要的是要想清楚工作邏輯、數據關聯與取樣設計。

Fig. python sklearn 三個敍述即可取得由19個迴歸係數組合成的預測值。
經由三次方迴歸預測,CR30與i1Pro3的最大差距由1.79 de00 降到 0.63 de00,平均差距由0.91 降到 0.22 de00,是非常有効的訓練。

Fig. 72個訓練樣本,三次方(degree=3)、三項次(L,a,b)關聯,最大差距 0.63 de00,平均差距 0.22 de00

Fig. 三次方(degree=3)、三項次(L,a,b)關聯,L值的目標與預測

Fig. 三次方(degree=3)、三項次(L,a,b)關聯,a值的目標與預測

Fig. 三次方(degree=3)、三項次(L,a,b)關聯,b值的目標與預測
如此有效的訓練,最大差距 0.63 de00,平均差距 0.22 de00,這樣的數值差距堪比20萬級距的設備了,但這只是訓練組裏的樣本,其它的量測值一樣能達到這樣的成果嗎?
再測了三個不在訓練組的測試點,分別為Lab (50.69,65.07,47.67)、 (86.81,1.55,11.29)及(71.69,32.55,-0.15);CR30修正前差距為de00 2.14、2.42、1.61,一次方修正結果為1.10、1.83、0.49,有達到修正效果。三次方修正結果為0.52、1.87、0.55,除第二個樣本(86.81,1.55,11.29)修正有限,其它兩個樣本可以從2個de00修正0.5左右,算是很有効的修正。

Fig. Fogra media wedge 訓練組之外的三個樣本。

Fig. 訓練組外三個樣本的修正值,分一次方修正及三次方修正。
剛開始接觸 Machine learning,這樣的成果算是有達到我的預期。
之所以會帶出Machine learning這個題目,一開始,很單純的,手邊好幾個量測工具,只是希望它們的數據能夠更加一致。
把這個題目的使用場景繼續擴大,讓任意兩個量測儀器經由一套學習模式,數值能夠彼此接近。
一個場景可以是客戶與生成端的儀器互相學習,這樣在客戶與生產端各自使用儀器時,能更加相互信任,減少爭議。這樣的應用場景,也可以是生產單位綁定客戶的一種技術手段,這個場景的設定是,客戶用較低階的儀器向生產單位高階的儀器學習,客戶的這個學習成果,衹能針對他學習對象的單位,如此,生產單位即以此數據(對應表)來綁定客戶的忠誠度。
也可以是同一單位各個部門的儀器,統一學習一個目標;比如業務部門較低階的儀器去學習生產部門較高階的儀器。這樣運用的想像,可以撒出更多低階的儀器到各個部門,有助於把色彩即是數字的概念營造起來的同時,背後還能有一個精准度的支撐。
以這一次的學習案例已經能看到一些成效。但就如同前面所述,操作的方便性與精准度的要求還是必須找出一個平衡點。其實這一次測試,一次方的學習,也能帶來相當的效果;三次方的學雖然帶來了更好的結果,但在部署上相對複雜很多。
類似這樣子平衡點的取捨,諸如樣本訓練數量,樣本分佈方式,機器學習的工具運用……都還在嘗試當中。
另外一種想法是,用icc profile的操作概念:對色彩設備取樣訓練,透過icc profile,設備間的色彩就可以一致。
同樣的,對兩個儀器間做取樣訓練,建立兩個儀器間的profile(or look up table),透過icc profile的運作方式,兩個儀器間的數字就可以相互接近。
還有很多machine learning的工具還在摸索,這衹是個開頭,除了在儀器間數據一致性的應用之外,我也在想著能在這個產業的什麼地方也能用得上?比如印刷機的各種變數怎麼樣關聯到印刷機的調校週期?生產時的即時數據怎麼樣關聯到印前部門、管理部門及品管部門的操作策略?這些數據又怎麼關聯到客戶驗收的喜好度?
擺在眼前的是越來越便宜的計算能力,越來越強大的應用模組。但前提是要數據,即使是這類低階的儀器,不管再低階,它總是數據的開端。或許也是個機會,經由這些低階的色彩儀器,讓更多人建立起色彩即是數字的概念,讓這個產業的運作可以再往前前進一步。
13 12 月, 2022 › 色彩管理 › Administrator › no comments ›
RGB (driving) Printer CMS schema
一般家用印表機的列印,是經由驅動程式的各種選項來達成不同的色彩効果。對於一個要做色彩控制的人,在驅動程序上任何有關色彩的選項,對我來說都是一個黑盒子。

Fig . 驅動程式上的各種選項對我來說都是個黑盒子,從來不知道它會把我的色彩信息帶到什麼地方?

Fig. 就單純的想要印出一個C100的顏色都無法達到,一直給我一個黑盒子混出來的顏色。

Fig. 印刷機上單純的C100與M100。
這種以螢幕RGB為目標的驅動列印方式,我們且稱之為RGB印表機,相對於高階配有rip的CMYK印表機或是印刷機, RGB printer 的色彩控制反而更難執行。
儘管如i1 profiler也是有RGB Printer 的程序,還是可以形成Printer profile 來達成色彩管理的效果,但由於Printer Driver 的黑盒子選項及缺乏限墨及版調控制的能力,能做到什麼程度真的就是碰運氣;碰到好的墨水及紙張,是有機會取得好的結果,但真的就是碰運氣。

Fig. i1Profiler RGB 印表機程序
這次的測試,依照拉低門檻的精神:用的是最低階的印表機、副廠墨水、Open source 的profiling 軟體及儘可能最少格數的icc 導具,看看能做到什麼成効。
這次的 icc open source 用的是ArgyllCMS,衹要4個指令就可以取得icc profile。
1. targen -d2 -f411 PrinterName (target generation)
2. printtarg -ii1 -pA4 -t PrinterName (Print target)
3. chartread -c1 PrinterName (read chart)
4. colprof -D"Printer A" -qm PrinterName (color profiling)
4個指令各別配合幾個參數,這裡把工作程序及其指令參數依序說明。
1. targen // target generation 產出icc導具敍述。
-d // device 設備形式,2代表RGB印表機,1為CMYK 印表機。
-f // format 樣本格數,411 個樣本剛好塞滿一頁A4。
最後接印表機名稱(或是icc名稱),作為整個程序檔案名稱的依據。
2. printtarg // print target,依導具敘述形成圖檔。
-i // instrument 量測儀器,我用的是i1。
-p // page size,這裏用A4
-t // 輸出tiff 檔,如果沒這個標示的話,內定圖檔格式為postscript檔。
最後接印表機名稱。

Fig. icc 411格樣本導具。
2-1. 取得icc tiff檔後在photoshop列印輸出。

Fig. 列印時要記得關掉printer driver 裡的各種色彩選項(–>不做色彩管理)
列印時要記得關掉printer driver 裡的各種色彩選項(–>不做色彩管理),儘量避免driver 做出"黑盒子"的色彩干擾;選擇一個字面上"合理"的紙張設定,這裡真的就是碰運氣,主要就是試試放墨量是不是在自己的預期。有耐心,有時間的話就把每一種紙張選項都跑一遍,看看哪一個紙張選項的放墨量最合適。
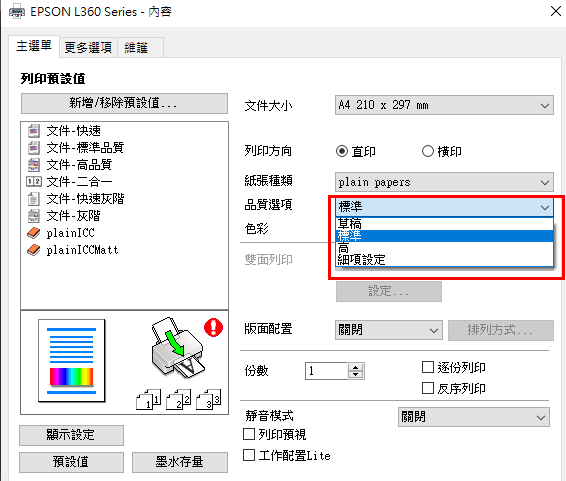
Fig. 紙張種類的選項影響到放墨量,看是要碰運氣還是花時間把全部跑過一趟。
列印出來之後用"chartread"指令讀取icc 導表的數據,再將數據交由下一個指令"colprof"計算出icc profile。
3. chartread // 讀取導表數據。
-c1 // c1 指的是由usb port取得數據。
4. colprof // color profiling,計算icc profile。
-D // Description, icc 檔案敍述,有別於 icc 檔名,當photoshop要去讀取icc的時候,看的是這個description的名稱,而不是檔案名稱。
-q // quality,這次給m, medium,還有 Low(l)、High(h)及Ultra(u)可選。
4個指令下來就可以得到icc profile。一般20分鐘左右就可以完成。
再次列印時即可在Photoshop 的列印功能裡調用此 icc profile。

Fig. 在Photoshop 的列印功能裡調用 icc profile。

Fig. 整個程序下來,列印結果還算滿意。
用CT25快速的檢測,除了Y100不夠好之外,其他部分都有拿到分數,以c9方式評分方式可以拿到92.5分,以gmi評分方式可以拿到90.67分,算是一個不錯的結果。

Fig. 以c9方式評分方式可以拿到92.5分。

Fig. 以gmi評分方式可以拿到90.67分。
以 G7 verifier檢測,可以達到Grayscale規範,調子及灰平衡的表現都算不錯。
Fig. 以G7 Verifier 檢測,階調"dL"及灰差"dCh"都有達標。
這次測試算是運氣好,也算是運氣不好。紙的條件還算可以,但黃色墨水的色相差太多。整體下來,可以達標C9/gmi,也可以達成G7 Grayscale。列印品質不差,ArgyllCMS 的icc 能力還是很不錯。

Fig. 噴墨印表機的Y墨嚴重偏紅,ArgyllCMS仍然可以把它拉到相差5.4de00的位置,我認為已經相當不錯了。
接下來比較大的問題是:RGB printer driver沒有限墨及線性(版調)的能力;這個能力能確保該列印設備能保有暗部的細節。高品質的面板比的是暗部細節的解析能力,同樣的,高品質的印刷比的一樣是暗部細節的解析能力。
ArgyllCMS是我目前唯一看到能處理RGB print driver限墨及綫性能力的icc 功具。
簡單講一下,它在印表機先取得一個綫性校正檔(calibration xx.cal),然後將這個校正檔結合到icc profile 裡,實現單一icc profile 同時具備限墨/線性及色彩轉換的能力。製作程序是比較麻煩,但使用起來是很方便的。
這裡也將這個綫性結合icc能力的工作方式依序描述一遍。
1. targen -d2 -f411 PrinterAcc ///產出RGB printer 的icc導具敍述。
2. targen -d2 -s20 -f0 PrinterA_c ///產出RGB 印表機(-d2) 20階綫性導具的敍述(-s20),-f0 代表這20階不做重覆排列(iteration)。
3. printtarg -ii1 -pA4 -t PrinterA_c ///將綫性導具輸出A4 tiff 圖檔。
4. 印出綫性tiff 圖檔(PrinterA_c.tif)。
5. chartread -c1 PrinterA_c ///由usb port 讀取線性導具數據。
6. printcal -p -i PrinterA_c ///依線性數據取得線性校正檔(PrintreA_c.cal)。-p plot,繪製綫性圖檔。-i initial, 初始校正。printcal 還有重複校正的能力,用-r。
7. printtarg -ii1 -pA4 -K PrinterA_c.cal -t PrinterAcc ///將校正檔(PrintreA_c.cal)結合印表機導具敘述輸出tiff格式的icc圖檔(PrinterAcc.tif);-K 表示後面要帶一個".cal" 綫性校正檔進來。
8. 將線性校正過的icc 圖檔(PrinterAcc.tif)列印出來。
9. chartread -c1 PrinterAcc ///讀取線性校正過的icc圖檔數據。
10. colprof -v -D"PrinterAcc" -qm PrinterAcc ///計算icc profile(PrinterAcc.icm)。
11. applycal PrinterA_c.cal PrinterAcc.icm PrinterA_cal.icm ///將線性檔(PrinterA_c.cal)結合到icc profile(PrinterAcc.icm)裡,產生一個新的icc(PrinterA_cal.icm)。
之後的列印祇要選取該 xxx_cal.icm profile 就可以同時實現線性與icc色彩轉換的功能。
下面示範幾個printcal(printer calibration)的能力:

Fig. printcal 限墨功能,經由數據判斷限墨位置,圖例顯示將C墨限制在85%左右。

Fig. printcal 線性功能

Fig.經由printcal限墨及線性功能,綫性導具的層次更加分明,綫性後的profile能在暗部帶出更多層次。

Fig. 左為未綫性化的icc導具,右為綫性化後的icc 導具,可以看出綫性化後的導具階調更為分明。

Fig. RBG printer 的線性導具轉到CMY放墨時是互補色的概念
RBG printer 的線性導具轉到CMY放墨時是互補色的概念;要下C100的墨,RGB的組合為0,255,255;範例樣本經由printcal 限墨,C最多下到35,255,255 換算成TV"Tone Value"值太約在 85%。
100%與255的換算式如下:
TV255=((100-TV%)/100)*255
經由ArgyllCMS線性化功能,RGB printer 的色彩控制能力更加能夠掌握,唯K墨的介入方式還是不明。所以,距全面的控制,還是差了一步。
但儘管如此,以這次的測試狀況,如果能拿到色相更好的Y墨,要達到ISO 12647-7的數位打樣規範,應該不是問題。
這一整篇下來,用最低階的家用印表機,配合open source的icc工具,如果能取得適當的紙張跟墨水,還是有很大的機會能達成ISO 12647-7的數位打樣規範。
還有一個更重要的訊息:對於很多沒有RIP支援的輸出設備,經由printer driver加上ArgyllCMS,一樣能具備相當程度的色彩控制。
Tags: inkjet, RGB printer
13 12 月, 2022 › 色彩管理, G7, 印刷標準化, 數位典藏 › Administrator › no comments ›
RGB (driving) Printer CMS schema
一般家用印表機的列印,是經由驅動程式的各種選項來達成不同的色彩効果。對於一個要做色彩控制的人,在驅動程序上任何有關色彩的選項,對我來說都是一個黑盒子。
Fig . 驅動程式上的各種選項對我來說都是個黑盒子,從來不知道它會把我的色彩信息帶到什麼地方?
Fig. 就單純的想要印出一個C100的顏色都無法達到,一直給我一個黑盒子混出來的顏色。
Fig. 印刷機上單純的C100與M100。
這種以螢幕RGB為目標的驅動列印方式,我們且稱之為RGB印表機,相對於高階配有rip的CMYK印表機或是印刷機, RGB printer 的色彩控制反而更難執行。
儘管如i1 profiler也是有RGB Printer 的程序,還是可以形成Printer profile 來達成色彩管理的效果,但由於Printer Driver 的黑盒子選項及缺乏限墨及版調控制的能力,能做到什麼程度真的就是碰運氣;碰到好的墨水及紙張,是有機會取得好的結果,但真的就是碰運氣。
Fig. i1Profiler RGB 印表機程序
這次的測試,依照拉低門檻的精神:用的是最低階的印表機、副廠墨水、Open source 的profiling 軟體及儘可能最少格數的icc 導具,看看能做到什麼成効。
這次的 icc open source 用的是ArgyllCMS,衹要4個指令就可以取得icc profile。
1. targen -d2 -f411 PrinterName (target generation)
2. printtarg -ii1 -pA4 -t PrinterName (Print target)
3. chartread -c1 PrinterName (read chart)
4. colprof -D"Printer A" -qm PrinterName (color profiling)
4個指令各別配合幾個參數,這裡把工作程序及其指令參數依序說明。
1. targen // target generation 產出icc導具敍述。
-d // device 設備形式,2代表RGB印表機,1為CMYK 印表機。
-f // format 樣本格數,411 個樣本剛好塞滿一頁A4。
最後接印表機名稱(或是icc名稱),作為整個程序檔案名稱的依據。
2. printtarg // print target,依導具敘述形成圖檔。
-i // instrument 量測儀器,我用的是i1。
-p // page size,這裏用A4
-t // 輸出tiff 檔,如果沒這個標示的話,內定圖檔格式為postscript檔。
最後接印表機名稱。
Fig. icc 411格樣本導具。
2-1. 取得icc tiff檔後在photoshop列印輸出。
列印時要記得關掉printer driver 裡的各種色彩選項(–>不做色彩管理),儘量避免driver 做出"黑盒子"的色彩干擾;選擇一個字面上"合理"的紙張設定,這裡真的就是碰運氣,主要就是試試放墨量是不是在自己的預期。有耐心,有時間的話就把每一種紙張選項都跑一遍,看看哪一個紙張選項的放墨量最合適。
Fig. 紙張種類的選項影響到放墨量,看是要碰運氣還是花時間把全部跑過一趟。
列印出來之後用"chartread"指令讀取icc 導表的數據,再將數據交由下一個指令"colprof"計算出icc profile。
3. chartread // 讀取導表數據。
-c1 // c1 指的是由usb port取得數據。
4. colprof // color profiling,計算icc profile。
-D // Description, icc 檔案敍述,有別於 icc 檔名,當photoshop要去讀取icc的時候,看的是這個description的名稱,而不是檔案名稱。
-q // quality,這次給m, medium,還有 Low(l)、High(h)及Ultra(u)可選。
4個指令下來就可以得到icc profile。一般20分鐘左右就可以完成。
Fig. 整個程序下來,列印結果還算滿意。
用CT25快速的檢測,除了Y100不夠好之外,其他部分都有拿到分數,以c9方式評分方式可以拿到92.5分,以gmi評分方式可以拿到90.67分,算是一個不錯的結果。
Fig. 以c9方式評分方式可以拿到92.5分。
Fig. 以gmi評分方式可以拿到90.67分。
以 G7 verifier檢測,可以達到Grayscale規範,調子及灰平衡的表現都算不錯。
Fig. 以G7 Verifier 檢測,階調"dL"及灰差"dCh"都有達標。
這次測試算是運氣好,也算是運氣不好。紙的條件還算可以,但黃色墨水的色相差太多。整體下來,可以達標C9/gmi,也可以達成G7 Grayscale。列印品質不差,ArgyllCMS 的icc 能力還是很不錯。
Fig. 噴墨印表機的Y墨嚴重偏紅,ArgyllCMS仍然可以把它拉到相差5.4de00的位置,我認為已經相當不錯了。
接下來比較大的問題是:RGB printer driver沒有限墨及線性(版調)的能力;這個能力能確保該列印設備能保有暗部的細節。高品質的面板比的是暗部細節的解析能力,同樣的,高品質的印刷比的一樣是暗部細節的解析能力。
ArgyllCMS是我目前唯一看到能處理RGB print driver限墨及綫性能力的icc 功具。
簡單講一下,它在印表機先取得一個綫性校正檔(calibration xx.cal),然後將這個校正檔結合到icc profile 裡,實現單一icc profile 同時具備限墨/線性及色彩轉換的能力。製作程序是比較麻煩,但使用起來是很方便的。
這裡也將這個綫性結合icc能力的工作方式依序描述一遍。
1. targen -d2 -f411 PrinterAcc ///產出RGB printer 的icc導具敍述。
2. targen -d2 -s20 -f0 PrinterA_c ///產出RGB 印表機(-d2) 20階綫性導具的敍述(-s20),-f0 代表這20階不做重覆排列(iteration)。
3. printtarg -ii1 -pA4 -t PrinterA_c ///將綫性導具輸出A4 tiff 圖檔。
4. 印出綫性tiff 圖檔(PrinterA_c.tif)。
5. chartread -c1 PrinterA_c ///由usb port 讀取線性導具數據。
6. printcal -p -i PrinterA_c ///依線性數據取得線性校正檔(PrintreA_c.cal)。-p plot,繪製綫性圖檔。-i initial, 初始校正。printcal 還有重複校正的能力,用-r。
7. printtarg -ii1 -pA4 -K PrinterA_c.cal -t PrinterAcc ///將校正檔(PrintreA_c.cal)結合印表機導具敘述輸出tiff格式的icc圖檔(PrinterAcc.tif);-K 表示後面要帶一個".cal" 綫性校正檔進來。
8. 將線性校正過的icc 圖檔(PrinterAcc.tif)列印出來。
9. chartread -c1 PrinterAcc ///讀取線性校正過的icc圖檔數據。
10. colprof -v -D"PrinterAcc" -qm PrinterAcc ///計算icc profile(PrinterAcc.icm)。
11. applycal PrinterA_c.cal PrinterAcc.icm PrinterA_cal.icm ///將線性檔(PrinterA_c.cal)結合到icc profile(PrinterAcc.icm)裡,產生一個新的icc(PrinterA_cal.icm)。
之後的列印祇要選取該 xxx_cal.icm profile 就可以同時實現線性與icc色彩轉換的功能。
下面示範幾個printcal(printer calibration)的能力:
Fig. printcal 限墨功能,經由數據判斷限墨位置,圖例顯示將C墨限制在85%左右。
Fig. printcal 線性功能
Fig.經由printcal限墨及線性功能,綫性導具的層次更加分明,綫性後的profile能在暗部帶出更多層次。
Fig. 左為未綫性化的icc導具,右為綫性化後的icc 導具,可以看出綫性化後的導具階調更為分明。
RBG printer 的線性導具轉到CMY放墨時是互補色的概念;要下C100的墨,RGB的組合為0,255,255;範例樣本經由printcal 限墨,C最多下到35,255,255 換算成TV"Tone Value"值太約在 85%。
100%與255的換算式如下:
TV255=((100-TV%)/100)*255
經由ArgyllCMS線性化功能,RGB printer 的色彩控制能力更加能夠掌握,唯K墨的介入方式還是不明。所以,距全面的控制,還是差了一步。
但儘管如此,以這次的測試狀況,如果能拿到色相更好的Y墨,要達到ISO 12647-7的數位打樣規範,應該不是問題。
這一整篇下來,用最低階的家用印表機,配合open source的icc工具,如果能取得適當的紙張跟墨水,還是有很大的機會能達成ISO 12647-7的數位打樣規範。
還有一個更重要的訊息:對於很多沒有RIP支援的輸出設備,經由printer driver加上ArgyllCMS,一樣能具備相當程度的色彩控制。
Tags: inkjet, RGB printer
20 11 月, 2022 › Uncategorized › Administrator › no comments ›
Press quality diagnostic without control patches.

印刷廠的客訴案,要我給點意見。
壓在下面的是印刷成品,上面那本是樣書。
首先,印刷成品的顔色沒跟上樣書,自然是印刷廠不對;不管樣書的産生符不符合規範,只要是客户認可的樣,就該照客户的樣來生産。
再來才是客觀數據的討論;當生產品與打樣顏色不一樣時,也是有可能樣書的製作是有問題的。
要做到客觀的判斷,必須先去了解原始稿件的色彩資訊。
取得原始檔案後,最快的判斷方式是在一個校正過的顯示系統裏比對。比對結果,樣書的颜色比較接近顯示器的颜色,初步判定,樣書程序相對没有問題,是印刷生產出了問題。

Fig. 左為印刷成品,右為樣書,中間螢幕顯示。螢幕顯示比較接近樣書。
從數據端觀察,以CRPC6 為標的,封面底色M85Y95 的色彩值為 Lab 52,59,49。實際取得樣書的色彩值為51.37,62.67,49.43, de00 1.42,顯示樣書的色彩品質還算不錯。印刷成品的色彩值為49.41,63.9,45.19,de00 4.17。從這裡很清楚,是生產品出了問題。
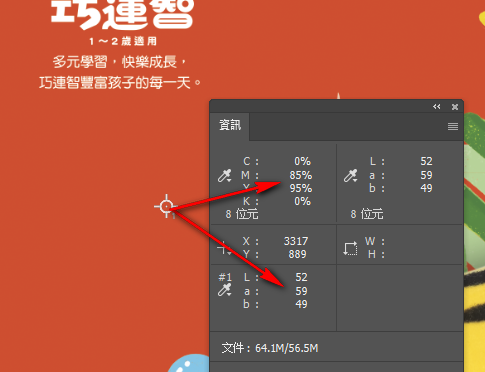

Fig. 樣書M85Y95與CRPC6差1.42 de00,印刷成品與CRPC6差4.17 de00。
可以清楚的確定是印刷的問題,那可以判斷是那些地方出問題嗎?
從視覺經驗可以很快猜測是M墨太多,這個M墨太多又有兩個方向的考量:是放墨量太多?還是網點擴張太大?
出版品中找不到M100的參考點,不過有找到一個M63的參考點。
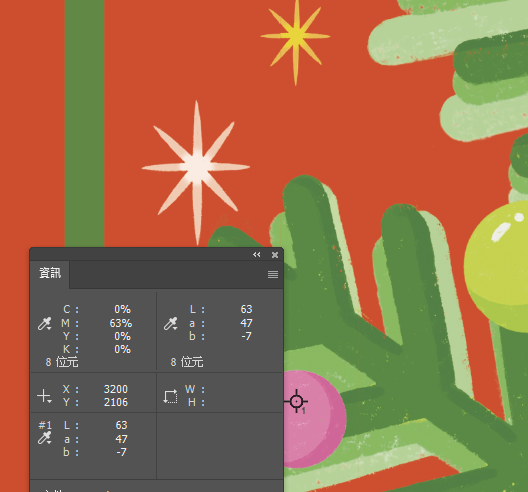

由數據顯示,在M63參考點生產品相對於樣書在飽和度多了4,版調(TV)多了3%,所以,印刷機的版調是太重了。
至於M100下墨有沒有太重?由於沒有參考點,所以不得而知;但以濃度與TV值的推算,大概還是可以知道,M墨是下太重了。
繼續來檢討Y墨與C墨的印刷行為。
同樣的,檔案資料上找不到Y100與C100的參考點,衹能由幾個參考點來推測。
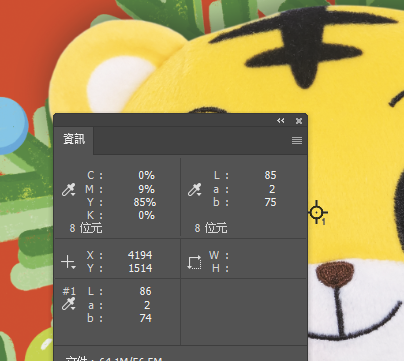

找到一個M9Y85的參考點來評估Y座狀態,從Lab值看,生產品的a值比較大,符合前段M墨放太多的假設。b值變小了,有可能是生產品的Y墨太少,也有可能是M9過多的網點擴張將b值往下帶;參考飽合度下降(84->75)及色角度偏離(86.87->85.27),M9還是有一定的影響,所以,Y墨在生產品是否太少還無法完全定論。
再來看C墨狀態,沒有C100參考點,找了一個C58Y4的參考點,
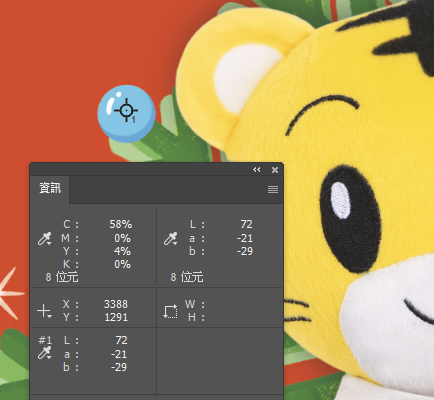

從版調(TV)看,生產品比樣書多了5%,這裡可以清楚看到,生產品的C墨也是太多了。
綜合以上,相對於樣書,生產品的C墨M墨太重,Y墨可能不足。
將這個原則運用到其他的測試點驗證。

參考點C95M75Y7,a 值由樣書的5.6拉到13,符合印刷操作M墨太多的假設,L值由30降到26也顯示CM過多帶來的影響。

參考點C33Y61,a值由樣書的-27到生產品的-35,符合印刷操作C墨太多的假設。b值由樣書的41到生產品的45,看來生產品在Y墨的中間調版調擴張太大;配合M9Y85參考點,生產品Y放墨不足,只能先理解成生產品Y滿版放墨不足但網點擴張還是偏大。

參考點C75M30Y100,a值由樣書的-27到生產品的-35,符合生產品C墨太多的假設,b值由35落後到生產品的19,理解為生產品CM太多降低b值,而滿版Y100也是不足的假設。


綜合以上,勉強定出結論為:生產品CM滿版及中間調都過多,Y墨則是滿版不足,但網點擴張偏大。
===============================================================
其實,寫了這麽多,真的想講的,只有一句話:把控制導表放進生產流程吧!

一方面師傅在操作時,依導具數據即可即時修正錯誤,就不會有這個客訴案件。
再者是在檢查錯誤時,幾分鐘的時間就可以知道問題在哪裏:知道滿版位置對不對?知道中間調對不對?而不是像這篇花了好多時間,衹能提供一個假設性的猜測。
20 11 月, 2022 › Fogra, G7, 印刷, 印刷標準化 › Administrator › no comments ›
Press quality diagnostic without control patches.
印刷廠的客訴案,要我給點意見。
壓在下面的是印刷成品,上面那本是樣書。
首先,印刷成品的顔色沒跟上樣書,自然是印刷廠不對;不管樣書的産生符不符合規範,只要是客户認可的樣,就該照客户的樣來生産。
再來才是客觀數據的討論;當生產品與打樣顏色不一樣時,也是有可能樣書的製作是有問題的。
要做到客觀的判斷,必須先去了解原始稿件的色彩資訊。
取得原始檔案後,最快的判斷方式是在一個校正過的顯示系統裏比對。比對結果,樣書的颜色比較接近顯示器的颜色,初步判定,樣書程序相對没有問題,是印刷生產出了問題。
Fig. 左為印刷成品,右為樣書,中間螢幕顯示。螢幕顯示比較接近樣書。
從數據端觀察,以CRPC6 為標的,封面底色M85Y95 的色彩值為 Lab 52,59,49。實際取得樣書的色彩值為51.37,62.67,49.43, de00 1.42,顯示樣書的色彩品質還算不錯。印刷成品的色彩值為49.41,63.9,45.19,de00 4.17。從這裡很清楚,是生產品出了問題。
Fig. 樣書M85Y95與CRPC6差1.42 de00,印刷成品與CRPC6差4.17 de00。
可以清楚的確定是印刷的問題,那可以判斷是那些地方出問題嗎?
從視覺經驗可以很快猜測是M墨太多,這個M墨太多又有兩個方向的考量:是放墨量太多?還是網點擴張太大?
出版品中找不到M100的參考點,不過有找到一個M63的參考點。
由數據顯示,在M63參考點生產品相對於樣書在飽和度多了4,版調(TV)多了3%,所以,印刷機的版調是太重了。
至於M100下墨有沒有太重?由於沒有參考點,所以不得而知;但以濃度與TV值的推算,大概還是可以知道,M墨是下太重了。
繼續來檢討Y墨與C墨的印刷行為。
同樣的,檔案資料上找不到Y100與C100的參考點,衹能由幾個參考點來推測。
找到一個M9Y85的參考點來評估Y座狀態,從Lab值看,生產品的a值比較大,符合前段M墨放太多的假設。b值變小了,有可能是生產品的Y墨太少,也有可能是M9過多的網點擴張將b值往下帶;參考飽合度下降(84->75)及色角度偏離(86.87->85.27),M9還是有一定的影響,所以,Y墨在生產品是否太少還無法完全定論。
再來看C墨狀態,沒有C100參考點,找了一個C58Y4的參考點,
從版調(TV)看,生產品比樣書多了5%,這裡可以清楚看到,生產品的C墨也是太多了。
綜合以上,相對於樣書,生產品的C墨M墨太重,Y墨可能不足。
將這個原則運用到其他的測試點驗證。
參考點C95M75Y7,a 值由樣書的5.6拉到13,符合印刷操作M墨太多的假設,L值由30降到26也顯示CM過多帶來的影響。
參考點C33Y61,a值由樣書的-27到生產品的-35,符合印刷操作C墨太多的假設。b值由樣書的41到生產品的45,看來生產品在Y墨的中間調版調擴張太大;配合M9Y85參考點,生產品Y放墨不足,只能先理解成生產品Y滿版放墨不足但網點擴張還是偏大。
參考點C75M30Y100,a值由樣書的-27到生產品的-35,符合生產品C墨太多的假設,b值由35落後到生產品的19,理解為生產品CM太多降低b值,而滿版Y100也是不足的假設。
綜合以上,勉強定出結論為:生產品CM滿版及中間調都過多,Y墨則是滿版不足,但網點擴張偏大。
===============================================================
其實,寫了這麽多,真的想講的,只有一句話:把控制導表放進生產流程吧!
一方面師傅在操作時,依導具數據即可即時修正錯誤,就不會有這個客訴案件。
再者是在檢查錯誤時,幾分鐘的時間就可以知道問題在哪裏:知道滿版位置對不對?知道中間調對不對?而不是像這篇花了好多時間,衹能提供一個假設性的猜測。
哼(ˉ(∞)ˉ)唧
去想試著尋找圖像裏判斷M墨的参考㸃,
在沒有控制色塊的情況下,從原始檔案資訊與成品上取得的色彩數據做參考分析,我們還能知道多少?其它色座有沒有問題?是滿版的問題大還是版調的問題比較大?
1 11 月, 2022 › Uncategorized › Administrator › no comments ›
data approaching via machine learning

i1以外的色彩量測儀器陸續在市場上出現,數據一致性這個問題避免不了!
這個問題衍生出幾個工作面向需要去處理。
一、什麼樣的差異是堪用的?1個de00?兩個de00?
我的看法:對要拿認證的廠,會要求到1個de00。資料上,Techkon SpectroDens 與 Xrite eXact 也是有1個de00的差距。
還有更多更多的廠、還沒有建立起數據觀念的廠,一些較低門檻的、兩個de00的敲門磚,我還是認可的。這些低門檻的設備,還是可以幫著帶到相當的位置。
以上圖中 Epson sd-10 、 CR30 跟 i1 的差距大約都是兩個de00;倒是 sd10 與 cr30 的差距還小一些,我的數據落在1.38 de00。

二、經由這些儀器將色彩解譯為數字,一旦是數字,我們就可以透過一些數學(統計學)程序來優化這些數字,讓儀器之間呈現的數值可以更接近。不管低階高階,對我來説,是有必要去找一個工作程序,讓兩個儀器的數字接近。
上次做過一次以紙白的光譜差別作為修正基礎,有取得一些改善成果,但多測試些樣本的時候,發現有的顏色的色差反而變大,這樣的結果還是不夠安全。就像某個藥品廣告說的:先求不傷身體,再來講求療效。同樣的,我必須先找一個比較保守的方法,至少色差不能變大,再來講究數據差的縮小。

這次經由以前的工作夥伴蔡同學處取得python Machine Learning 的樣版程式,想著這個對我 data approaching 這個題目應該有幚助。
再去多瞭解一些,看來就是很多統計學的函式庫,主要是在調用上顯得方便零活許多。內容很多,需要一些時間去消化理解。這次先試試 Multiple Regression 看看能有什麼成果。
首先,要怎麼餵資料就是一門學問:要多少樣本數?色彩樣本的分佈情況?樣本的參考點要設多少個?怎麼設?
一方面要增加精度、一方面又要讓操作儘量精簡;各種方面的考慮需要不斷的Trail and error去找到最佳的組合。

Fig. 這次用了16個樣本來學習。

Fig. 參考點取4個地方,分別是 460nm, 520nm, 630nm 及光譜反應總和(weight)。
依程序回測了三個樣本,大概就從2個de00拉到1個de00左右,算是有効的運作。

Fig. 樣本一,de00由 2.42降到1.42。

Fig. 樣本二,de00由 1.85降到1.18。

Fig. 樣本三,de00由 2.16降到1.27。
這次只是Machine learning 在 Data Approaching 的一個開端,各種machine learning 的運用還需要去更深入瞭解,樣本的取用邏輯及資料的餵法都還在嘗試及學習。
儀器間的數據迫近在我這邊會是一個長期的題目,隨著樣本收集方式的改進與對machine learning 能力的理解與運用,期待的是精度再提昇、操作方式更精簡。
計畫目標是隨時都能迫近到一個de00,會是以雲端平臺的方式提供服務;利用平臺的大量收據來繼續精進machine learning 的結果。這當中大量儀器的數據與機器學習之間的串接,還需要大量IT能力的支援。
先畫個餅,能實現到什麼程度我也不知道,總之,是該開始動起來了。
Tags: cr30, epson sd-10, machine learning


